解密AI知識庫
當(dāng)前位置:點晴教程→知識管理交流
→『 技術(shù)文檔交流 』
許多人對AI知識庫的理解是:只需將所有資料拖入AI客戶端(如Cherry Studio),AI便會自動閱讀并生成完美結(jié)論。
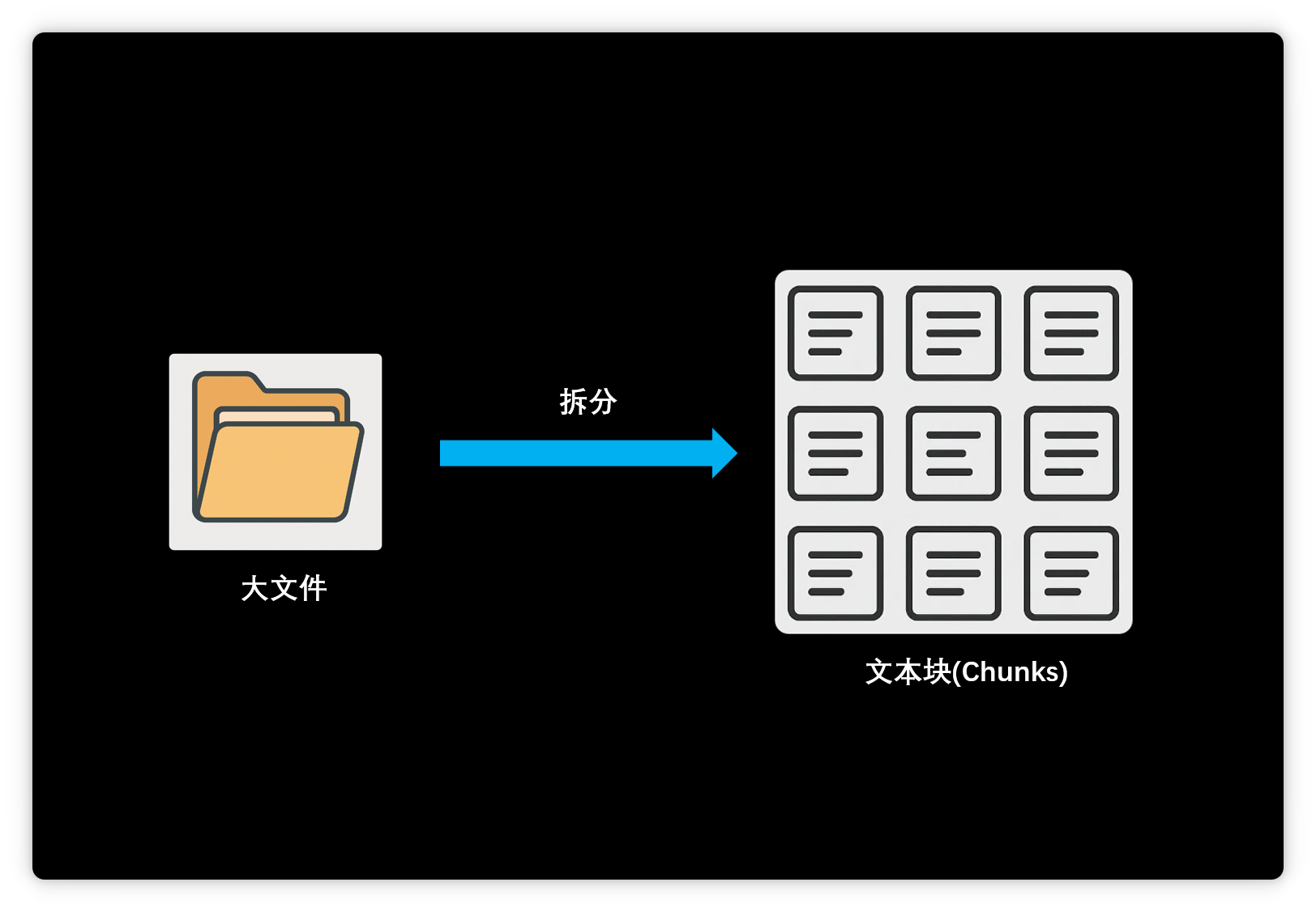
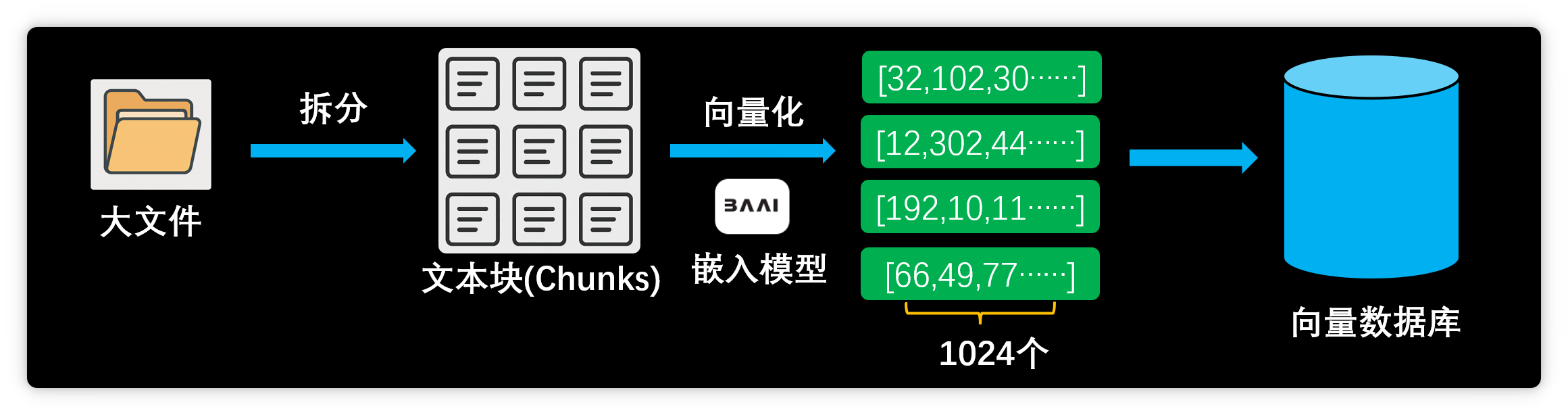
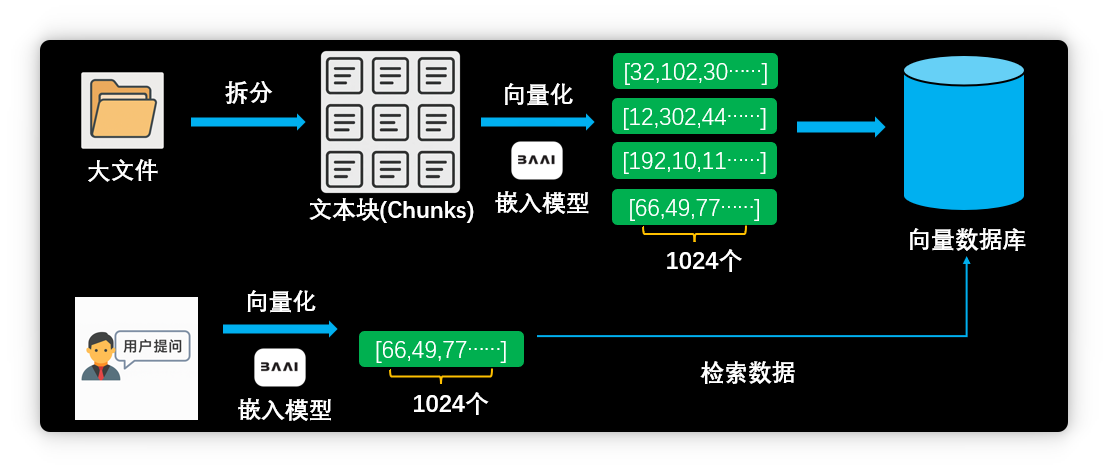
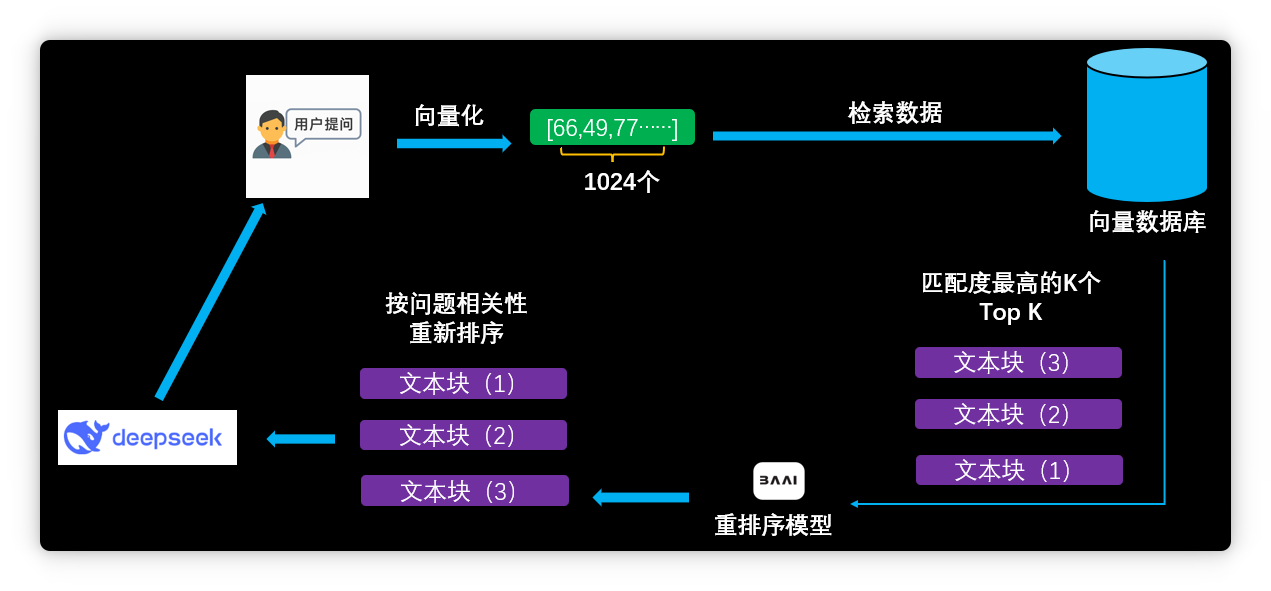
但實際體驗后,大家發(fā)現(xiàn)AI知識庫效果遠不如預(yù)期,經(jīng)常出現(xiàn)各種問題。 技術(shù)原理與局限本文將從原理出發(fā),分析AI知識庫的技術(shù)局限,并介紹進階方案,如重排序模型、數(shù)據(jù)庫(MCP server)和超長上下文模型等。 目前主流的大模型知識庫采用RAG(檢索增強生成)技術(shù)。 用戶添加資料時,系統(tǒng)會先將其拆分為多個文本塊。
隨后,嵌入模型將這些文本塊向量化,即將文本轉(zhuǎn)為一組超長數(shù)字序列。
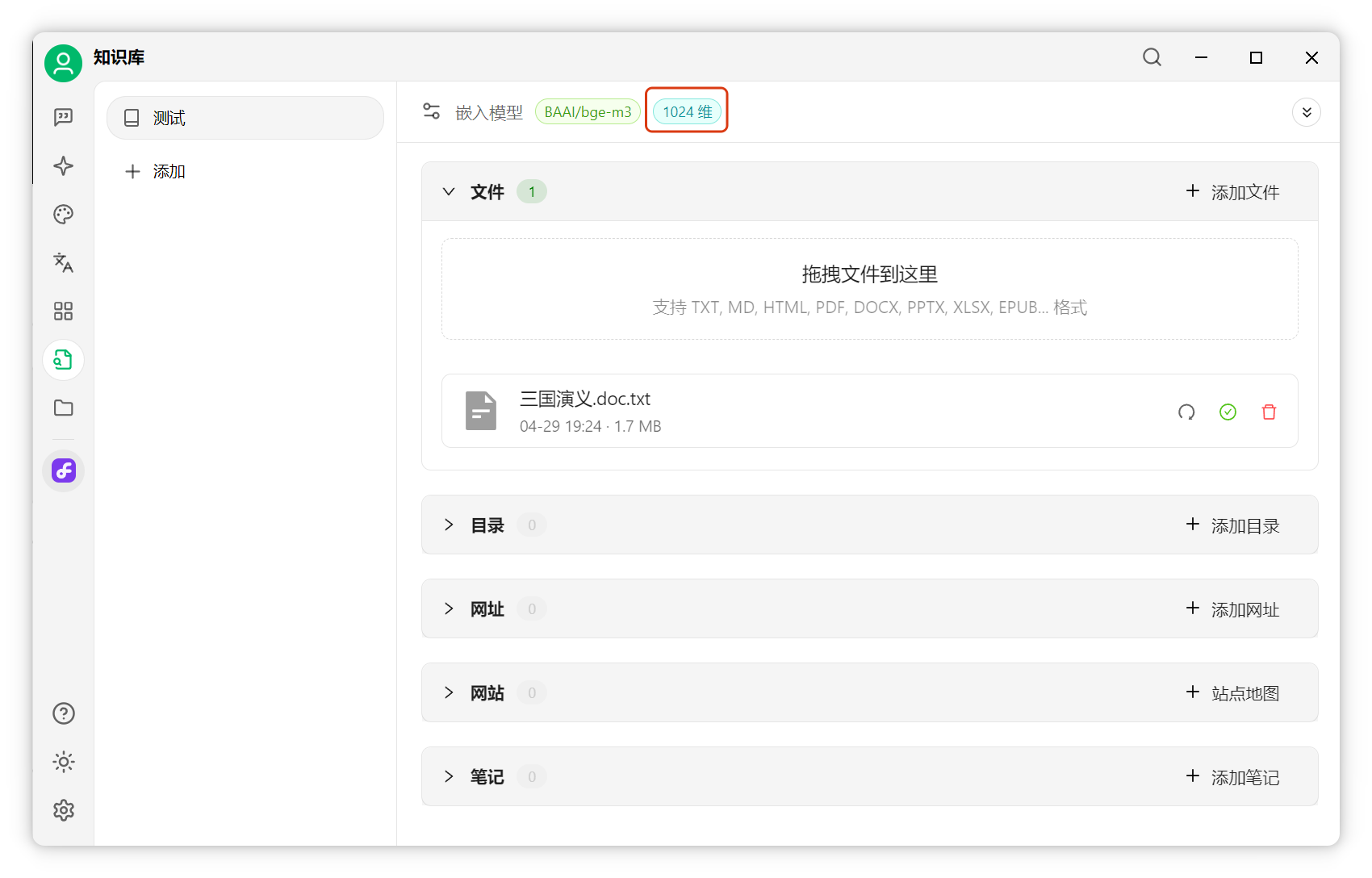
以我的知識庫為例,嵌入模型輸出1024維向量:
每個文本塊都被轉(zhuǎn)為1024個數(shù)值組成的向量:
系統(tǒng)將向量及對應(yīng)文本存入向量數(shù)據(jù)庫。
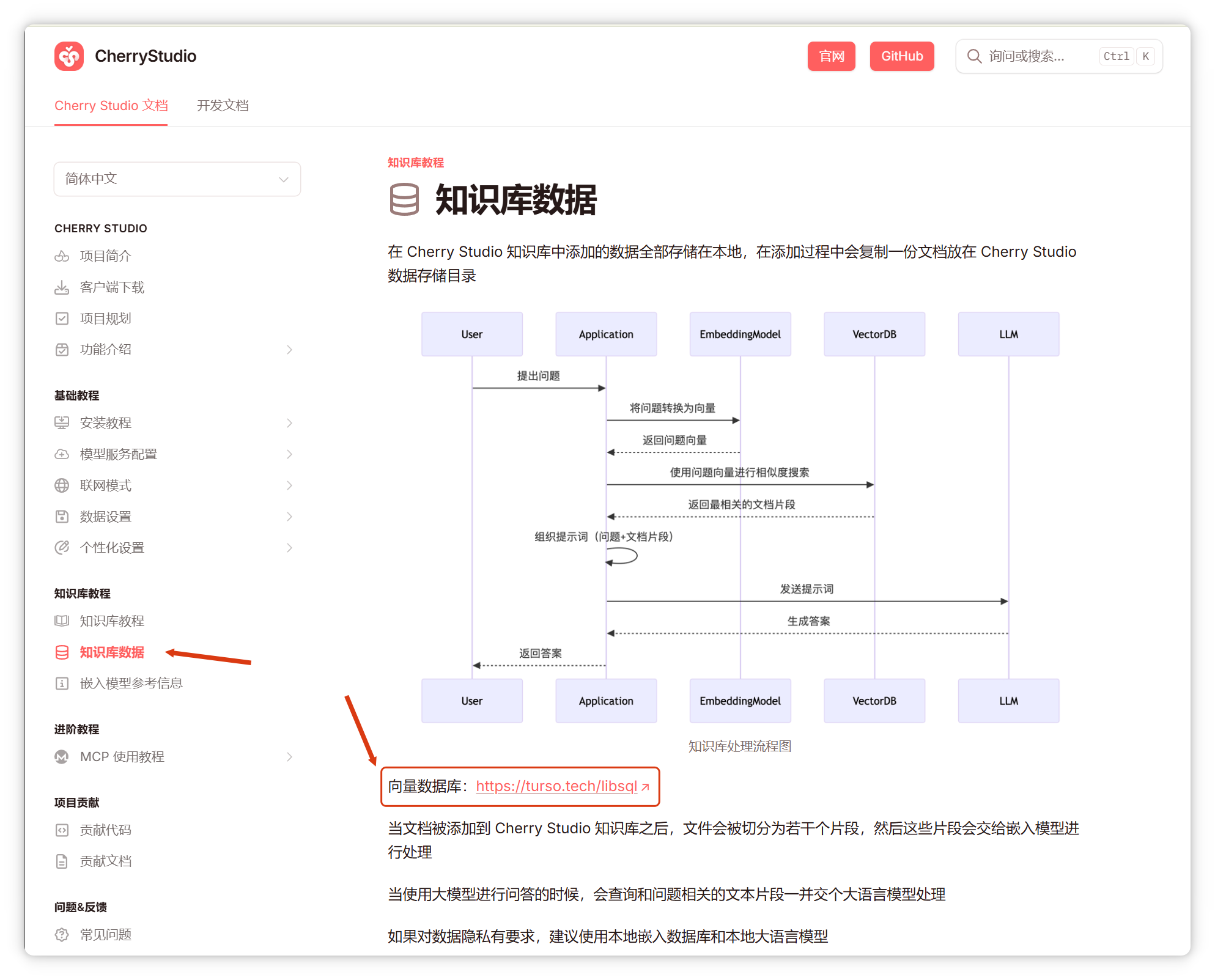
用戶提問時,問題同樣被向量化為1024維向量。
系統(tǒng)將問題向量與數(shù)據(jù)庫中所有向量進行相似度計算,完全基于數(shù)學(xué)運算。
最終,知識庫選出最相似的原文片段,與用戶問題一同發(fā)送給大模型,由其歸納總結(jié)。
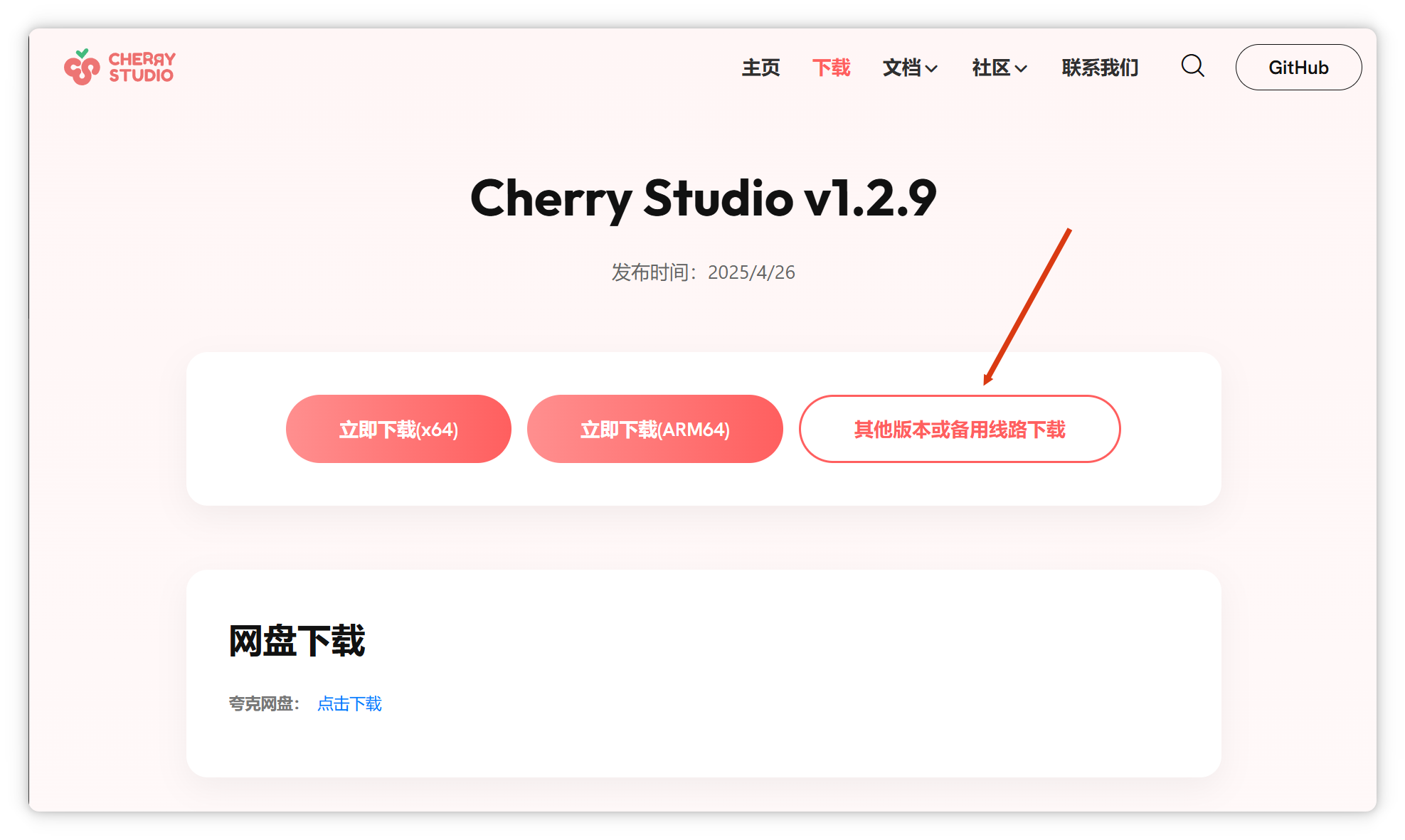
可見,在RAG架構(gòu)中,大模型主要負責(zé)歸納總結(jié),答復(fù)質(zhì)量很大程度取決于檢索精度。RAG系統(tǒng)普遍存在分塊粗糙、檢索不準(zhǔn)、缺乏全局視角等問題。 Cherry Studio安裝與配置前往Cherry Studio官網(wǎng)下載并安裝軟件:Cherry Studio
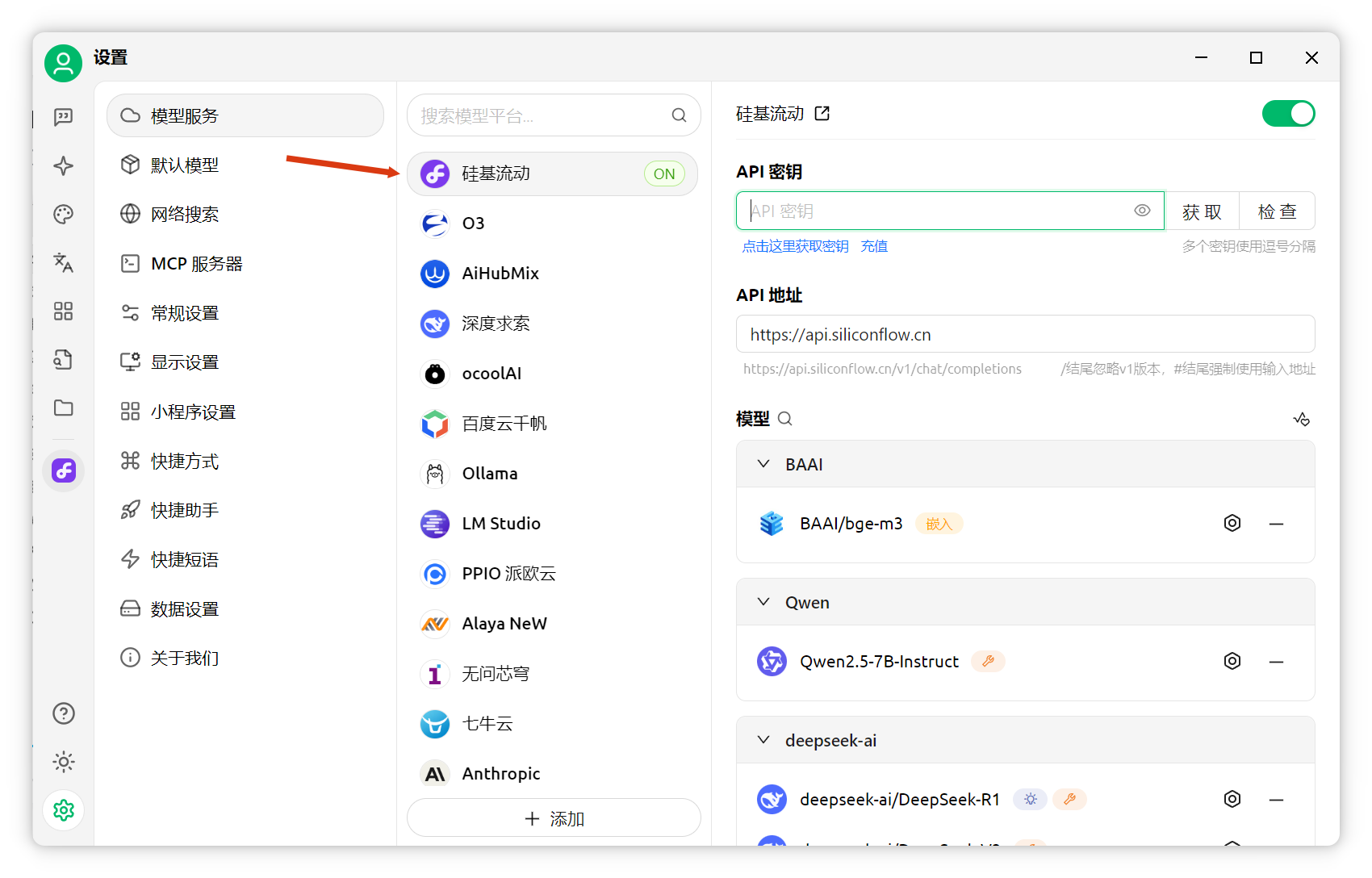
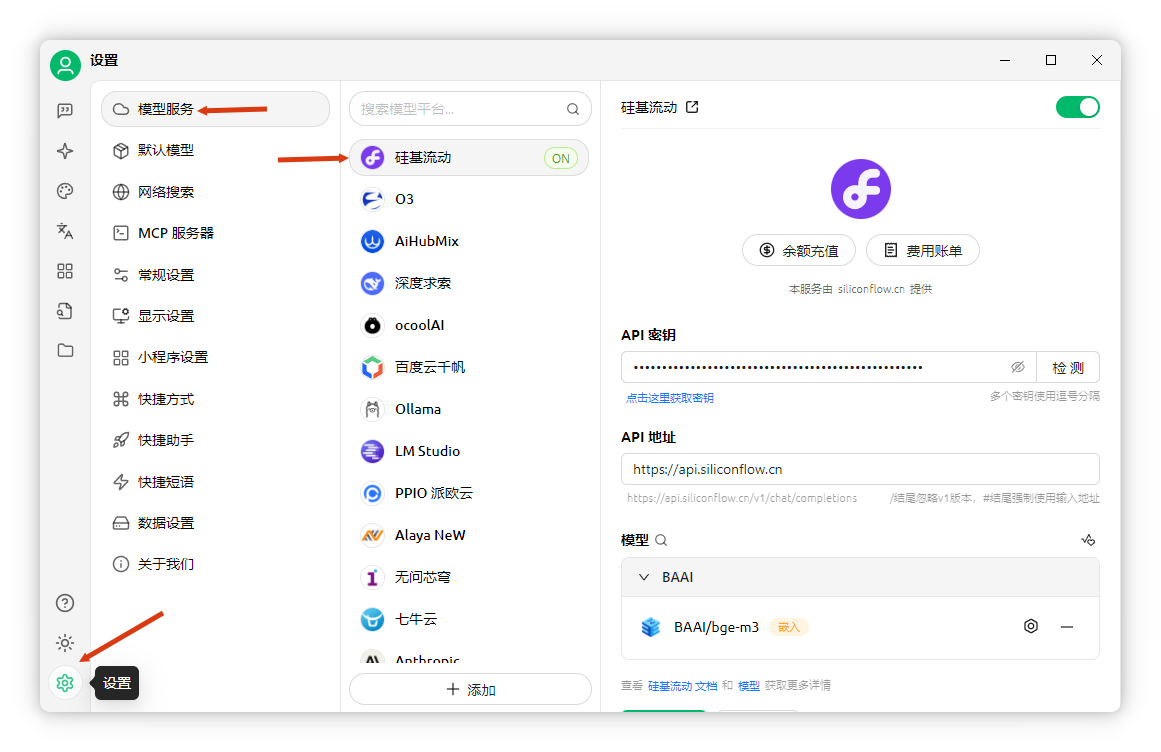
安裝過程簡單,按提示操作即可。 安裝后,打開軟件,點擊左下角“設(shè)置”-“模型服務(wù)”。
本文以硅基流動提供的免費嵌入模型為例。找到“硅基流動”,點擊獲取密鑰。若無賬號可先注冊。
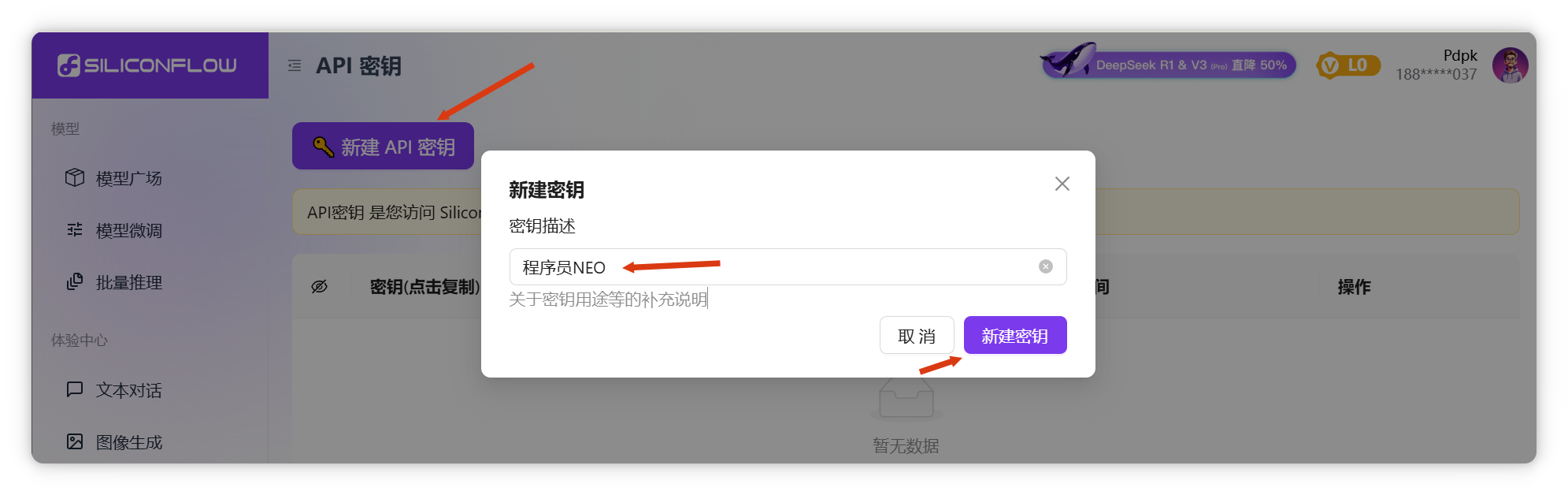
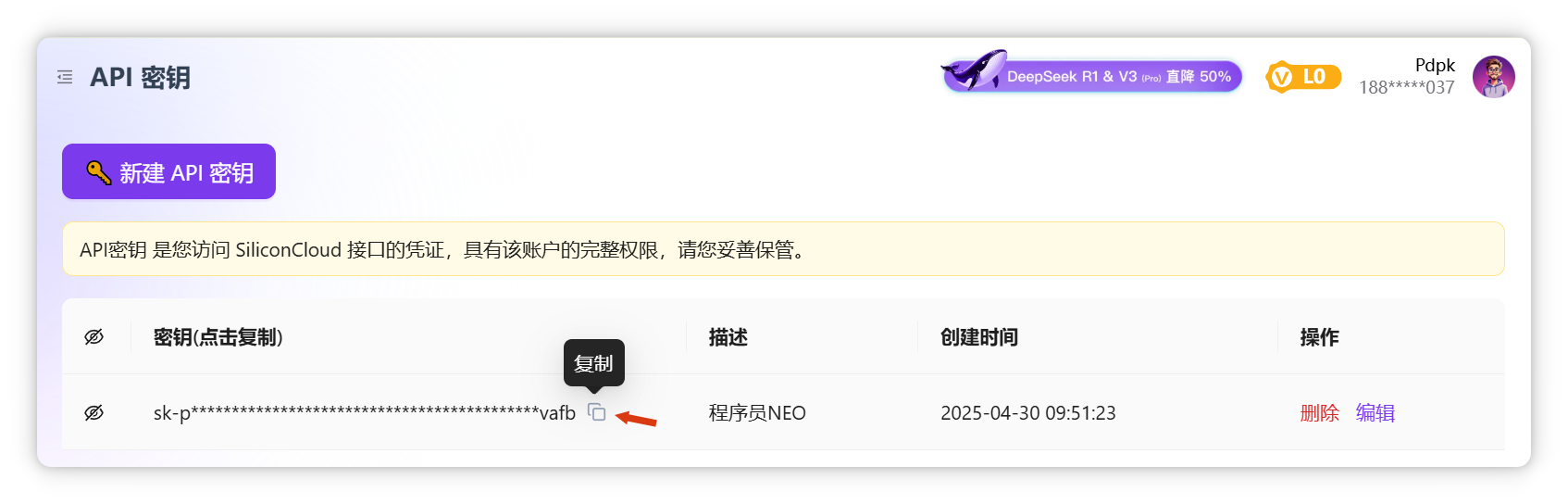
歡迎在評論區(qū)互助分享邀請碼。 點擊左側(cè)“API密鑰”,新建密鑰(如“程序員NEO”),復(fù)制生成的密鑰。
將密鑰填入Cherry Studio。
添加嵌入模型:點擊“模型”右側(cè)添加按鈕。
回到硅基流動“模型廣場”,篩選“類型”為“嵌入”,選擇“bge-m3(免費)”,復(fù)制模型名稱。
回到Cherry Studio,填入模型名,點擊“添加嵌入模型”完成配置。
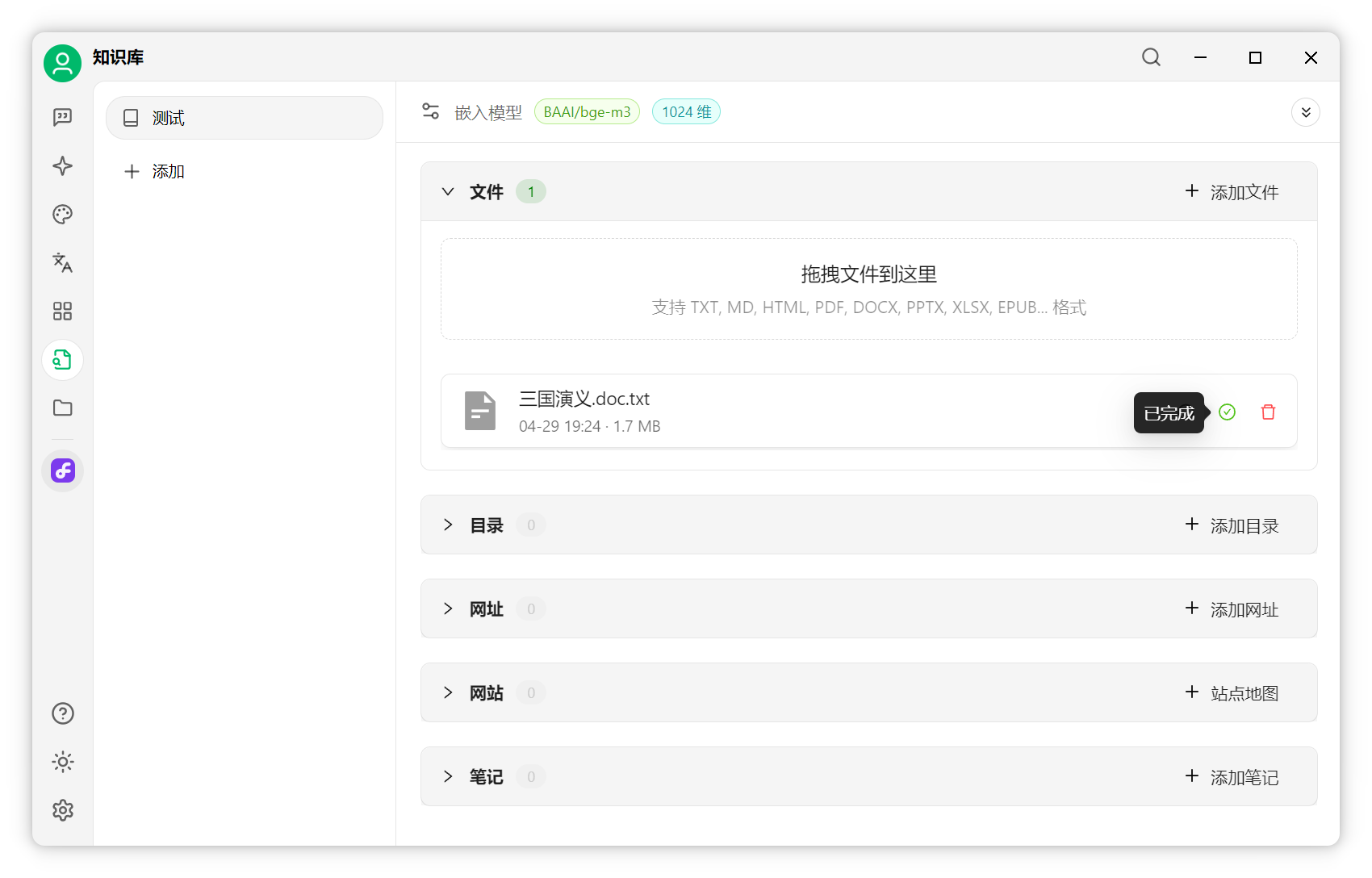
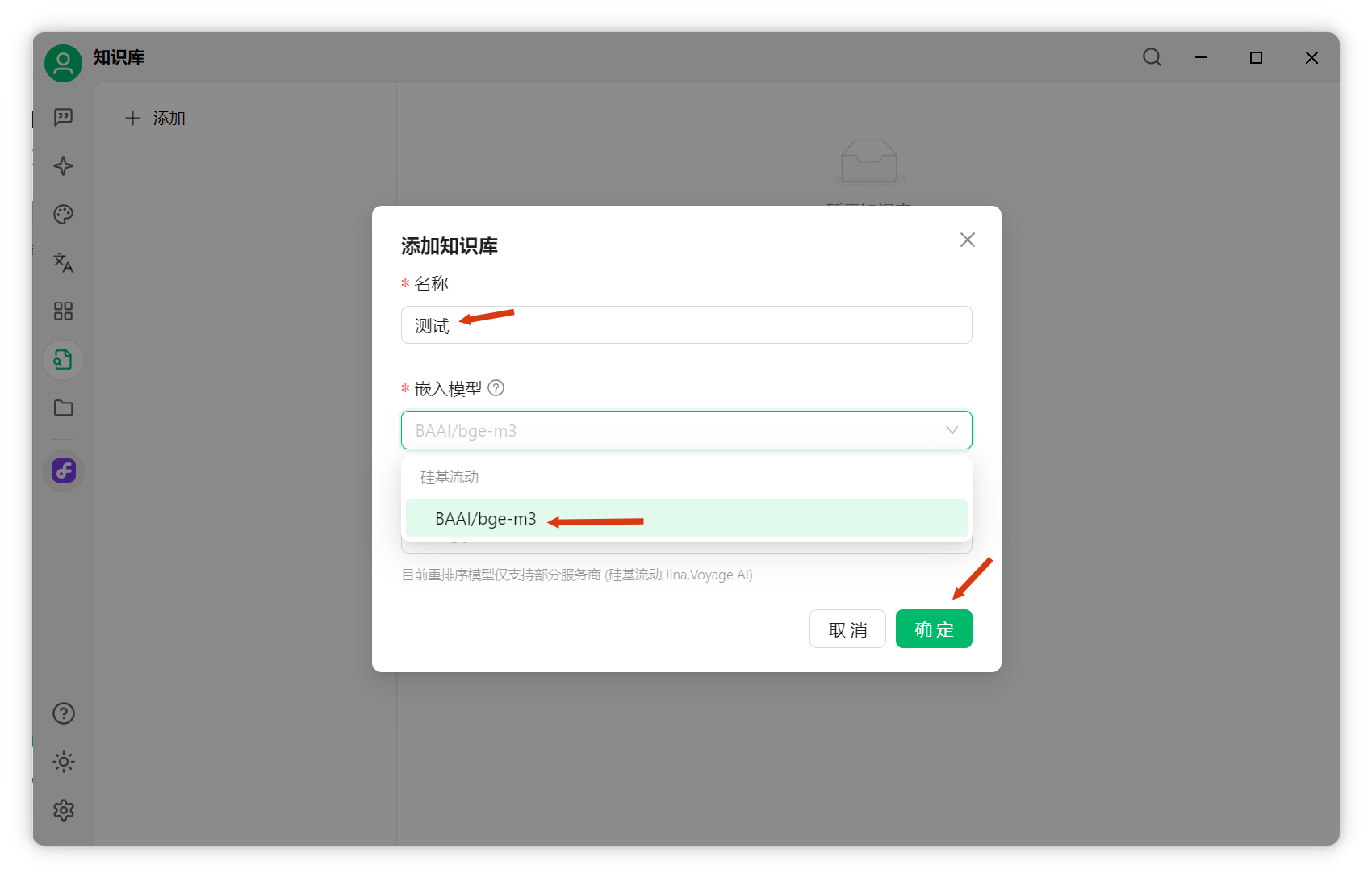
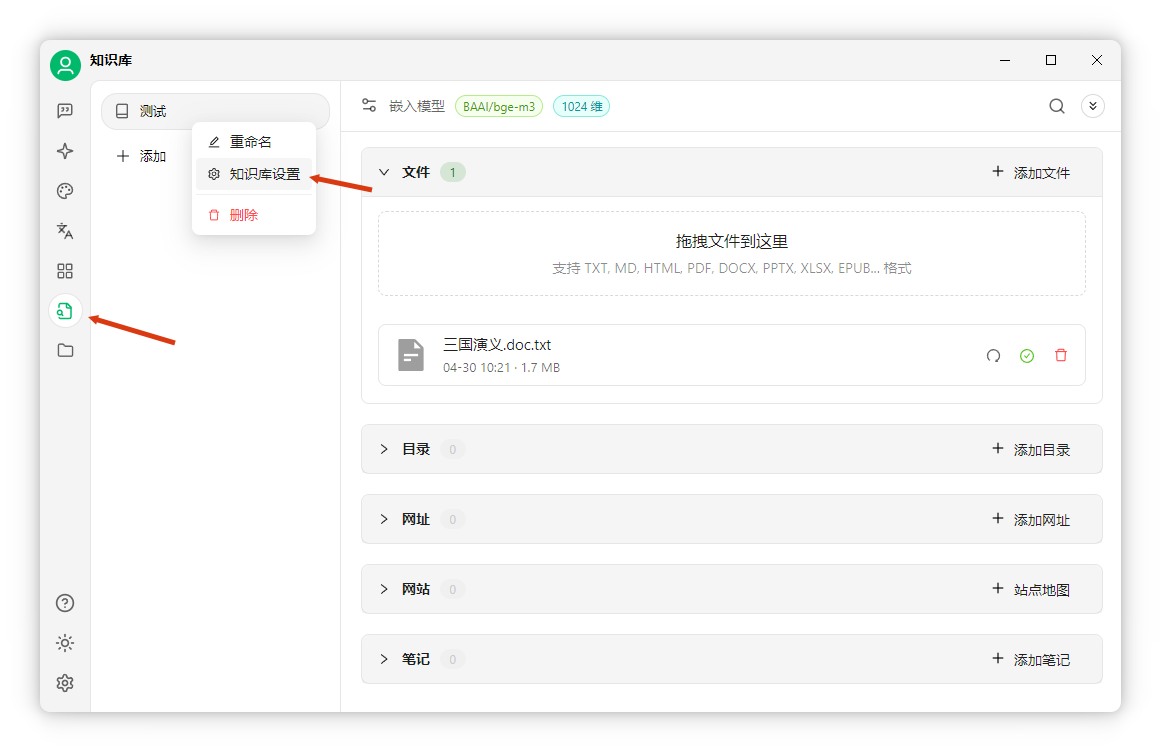
知識庫配置與文件添加配置知識庫:點擊左側(cè)“知識庫”-“添加”,填寫名稱,選擇剛添加的嵌入模型,點擊確定。
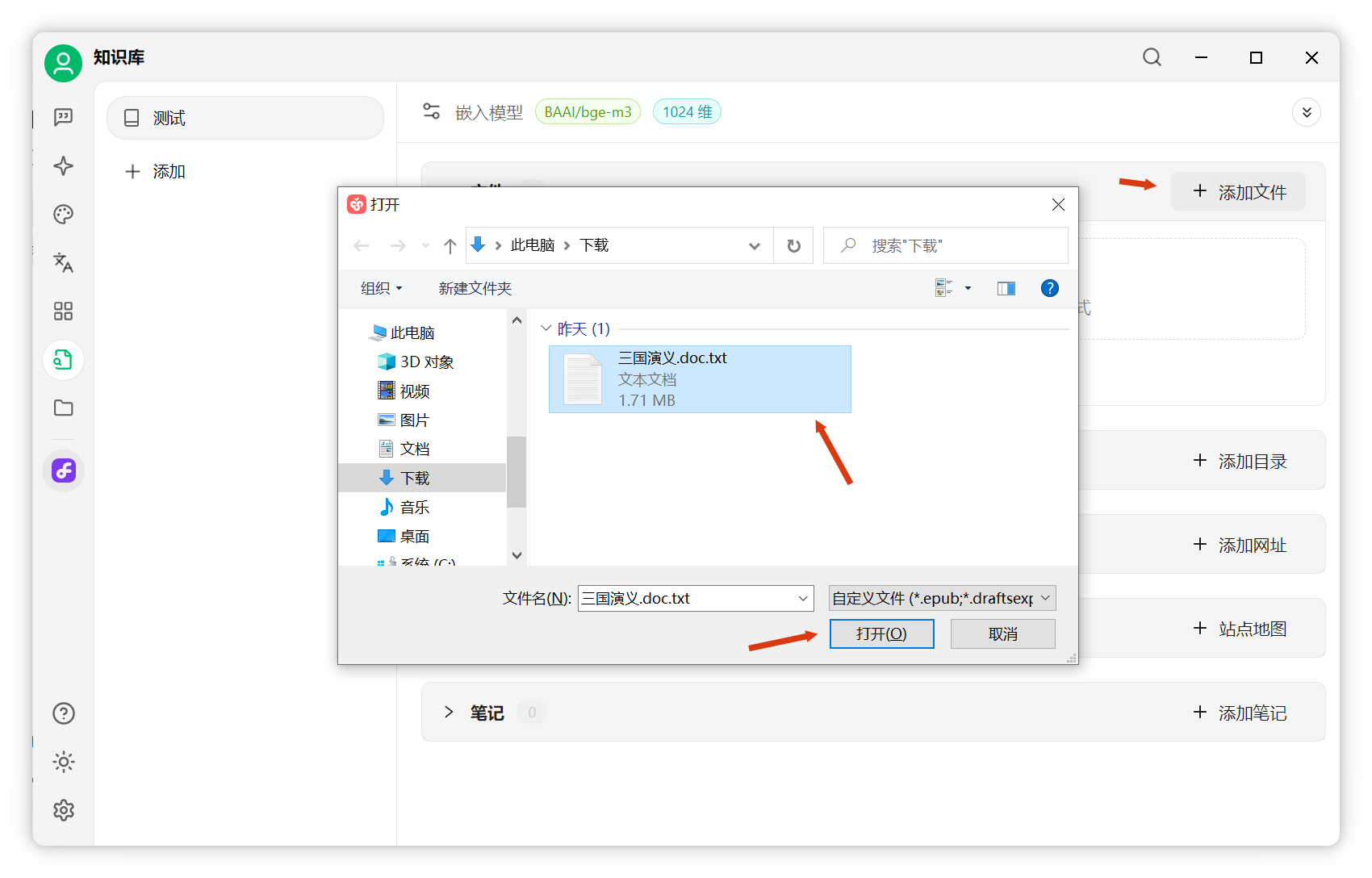
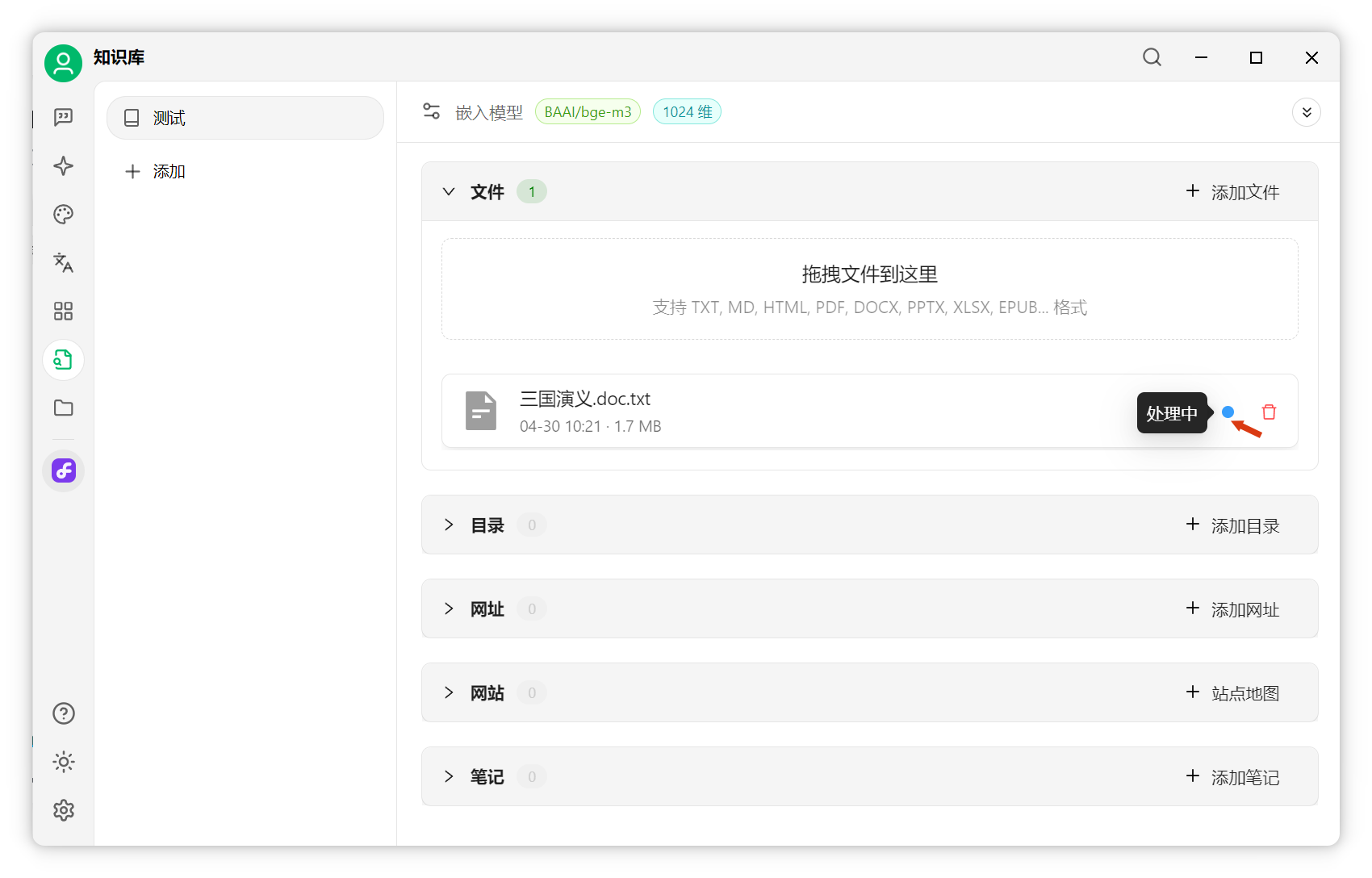
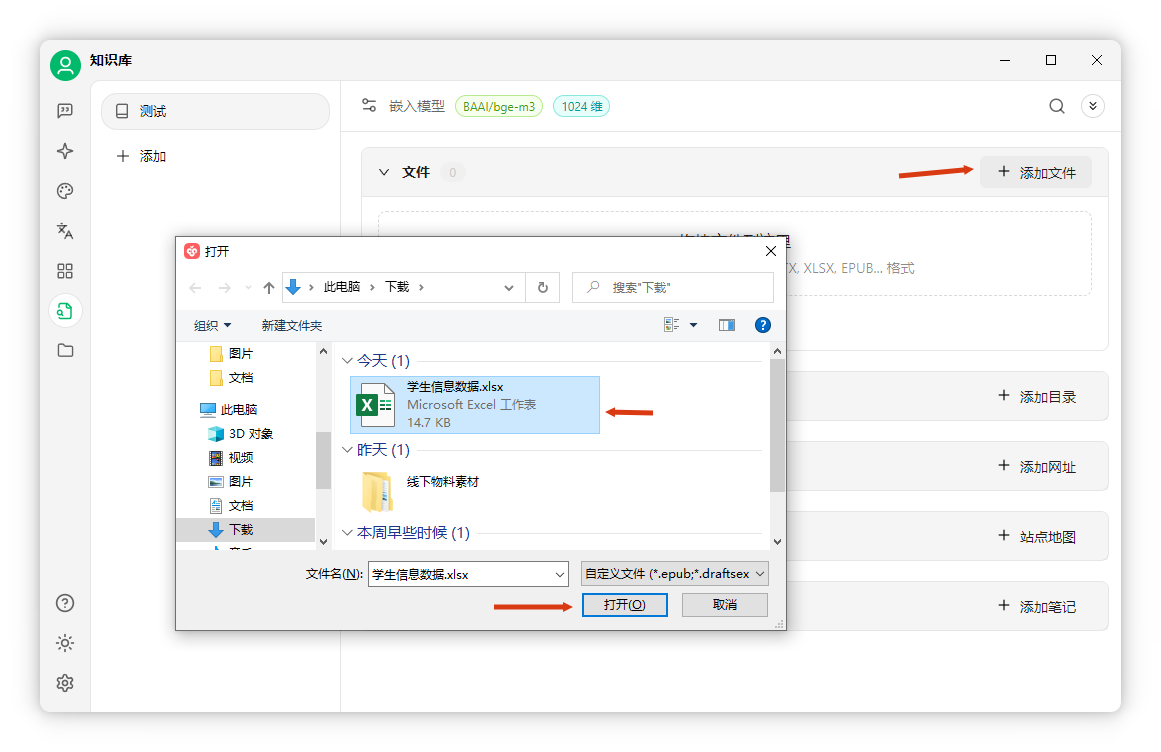
添加文件:點擊“添加文件”,選擇文檔(如《三國演義》),打開后自動處理。
分片已存入向量數(shù)據(jù)庫。
根據(jù)官方文檔,目前使用turso的libSQL數(shù)據(jù)庫。
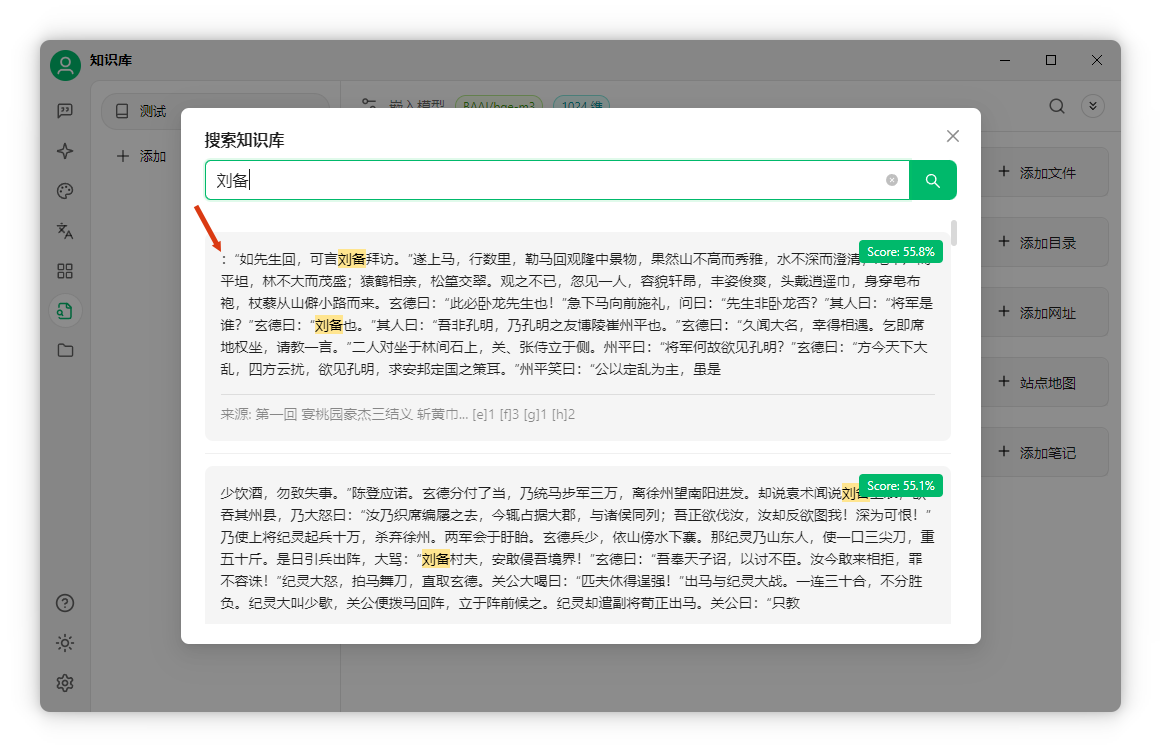
在知識庫頁面右上角點擊“搜索知識庫”可檢索分片內(nèi)容。
如搜索“劉備”,系統(tǒng)會基于向量匹配查找相關(guān)段落,每段約300字。
Cherry Studio采用long chain遞歸文本分割器。
RAG知識庫的缺陷與改進分塊方式簡單這種分塊方式基本按段落分塊,段落過長則按固定字?jǐn)?shù)切分,常導(dǎo)致句子被截斷。 以剛檢索到的“劉備”為例:
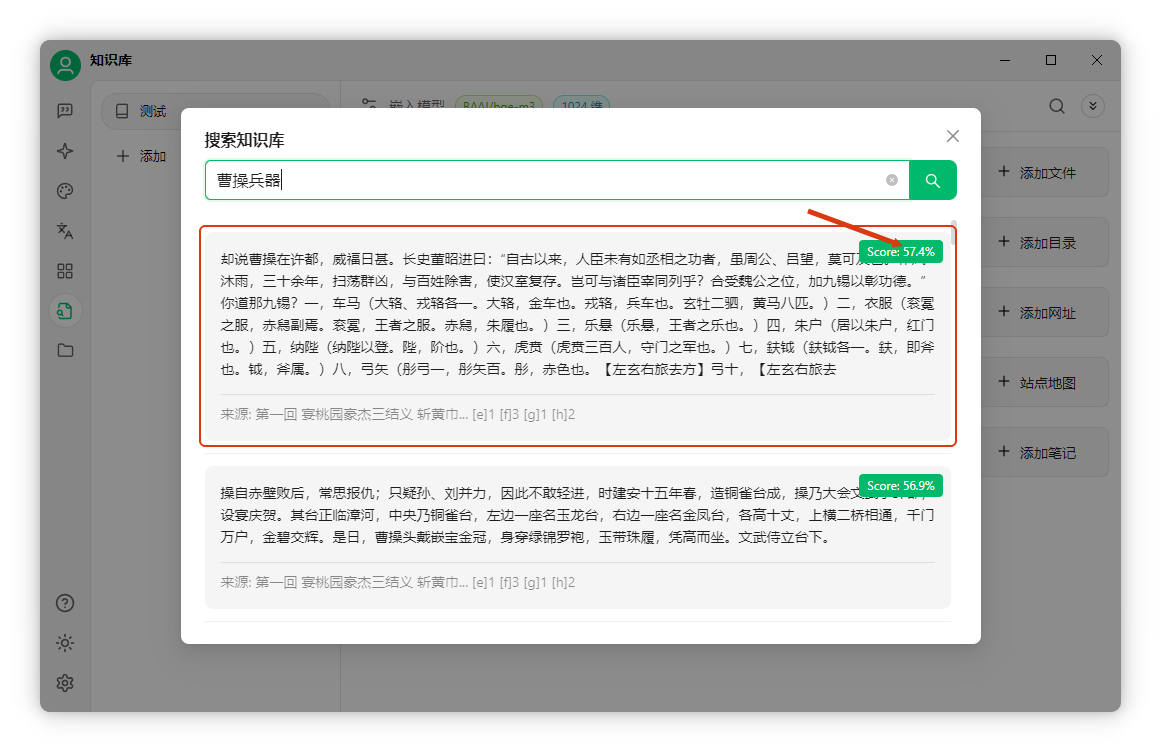
可見“:”前內(nèi)容被截斷,結(jié)尾“雖是”也未說完。由于分塊上限為300字,前后句被強行截斷。 這暴露了RAG知識庫的缺陷:分塊粗糙,AI難以理解上下文,導(dǎo)致回答不精準(zhǔn)。 雖然也有基于語義分析的分塊方法,但目前大多不成熟,效果甚至不如簡單分割。 檢索不精準(zhǔn)RAG的另一個問題是檢索不準(zhǔn)。例如搜索“曹操兵器”,想找倚天劍的信息。 系統(tǒng)僅基于數(shù)字相似度匹配,無法真正理解文本含義,篩選片段可能相關(guān)也可能無關(guān),難以精準(zhǔn)匹配。
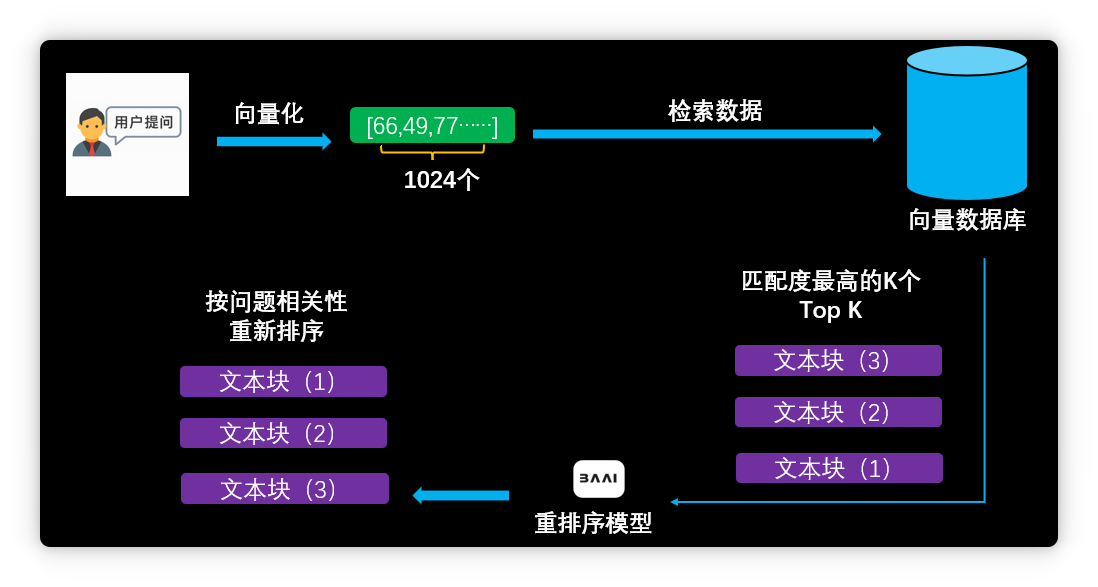
匹配結(jié)果往往不是所需信息,這是RAG系統(tǒng)的痛點之一。 較好的改進方案是引入重排序模型。先用向量數(shù)據(jù)庫初步檢索,再用重排序模型做語義分析,根據(jù)相關(guān)性重新排序。
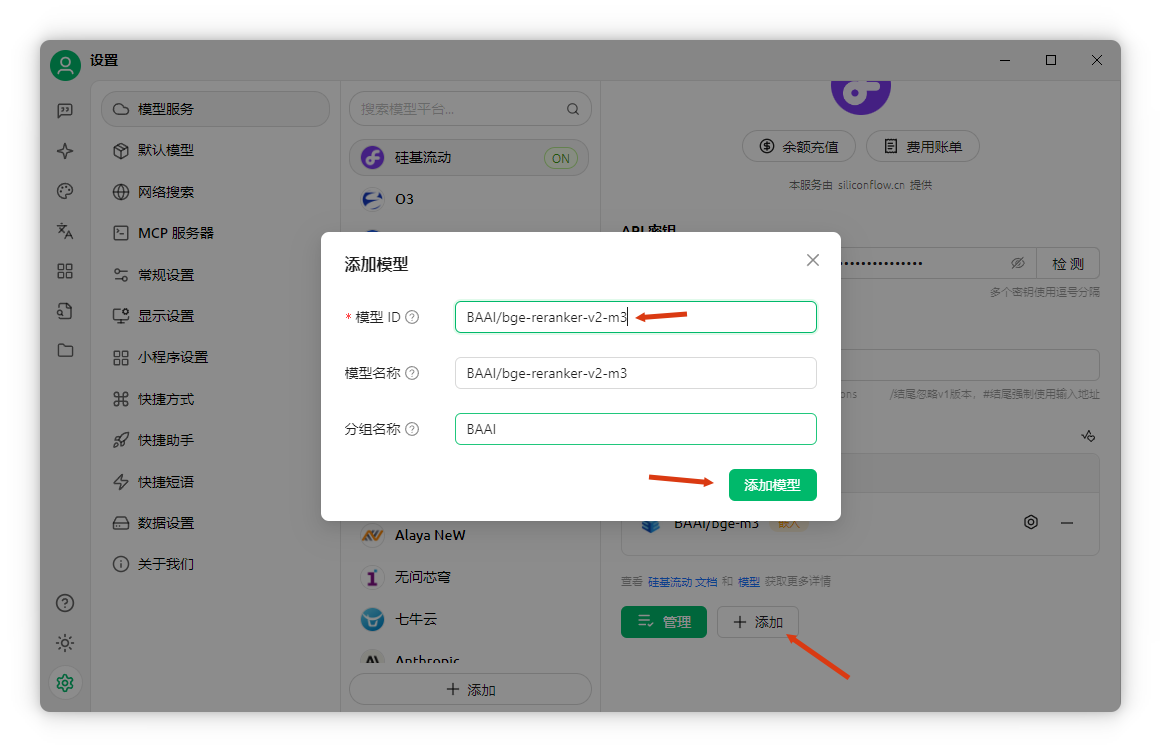
以“曹操兵器”為例,添加重排序模型后,效果明顯提升。進入模型服務(wù),找到硅基流動,添加重排序模型。
復(fù)制免費重排序模型名稱,回到Cherry Studio添加。
在知識庫設(shè)置中添加重排序模型,點擊確定。
再次搜索“曹操兵器”,倚天劍信息排到第二位,分?jǐn)?shù)78%。重排序模型顯著提升了檢索精度。
缺乏全局視角第三個痛點是缺乏全局視角。以AI生成的300條學(xué)生統(tǒng)計數(shù)據(jù)為例:
如需統(tǒng)計分析(如最大最小值),RAG難以勝任。向量數(shù)據(jù)庫只能匹配文本塊,無法整體分析。 將Excel文件添加到知識庫:
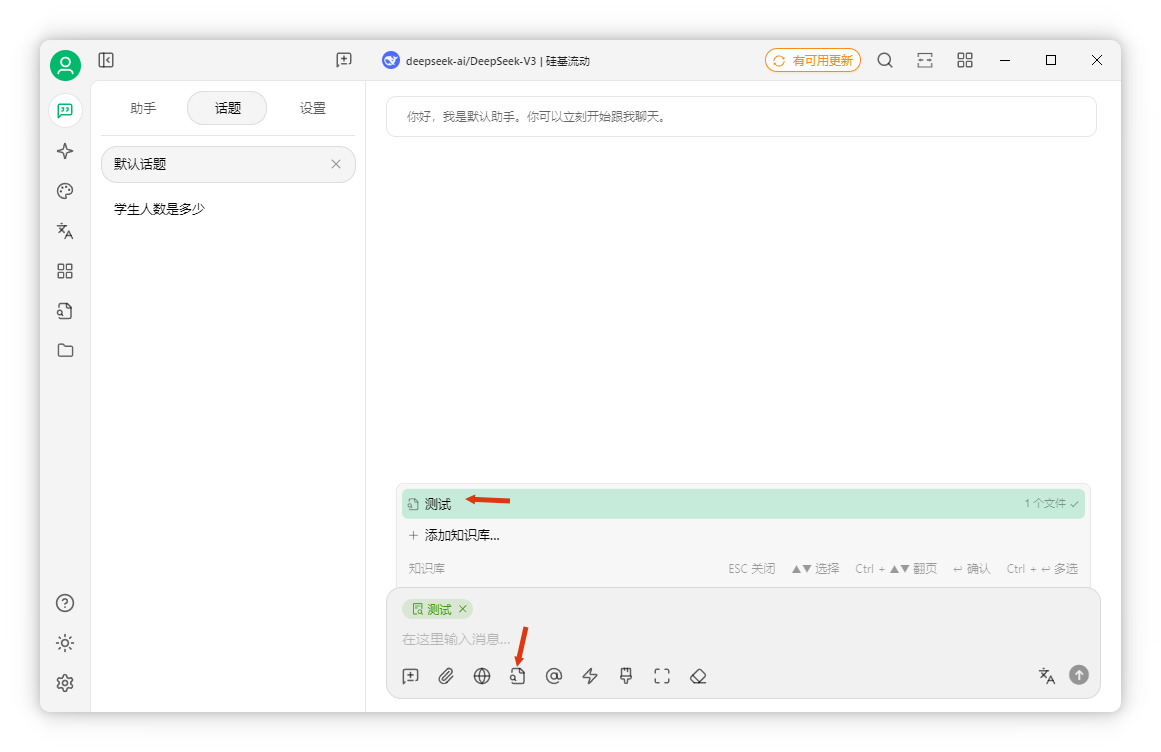
在聊天界面(使用DeepSeek,硅基流動提供),開啟知識庫。
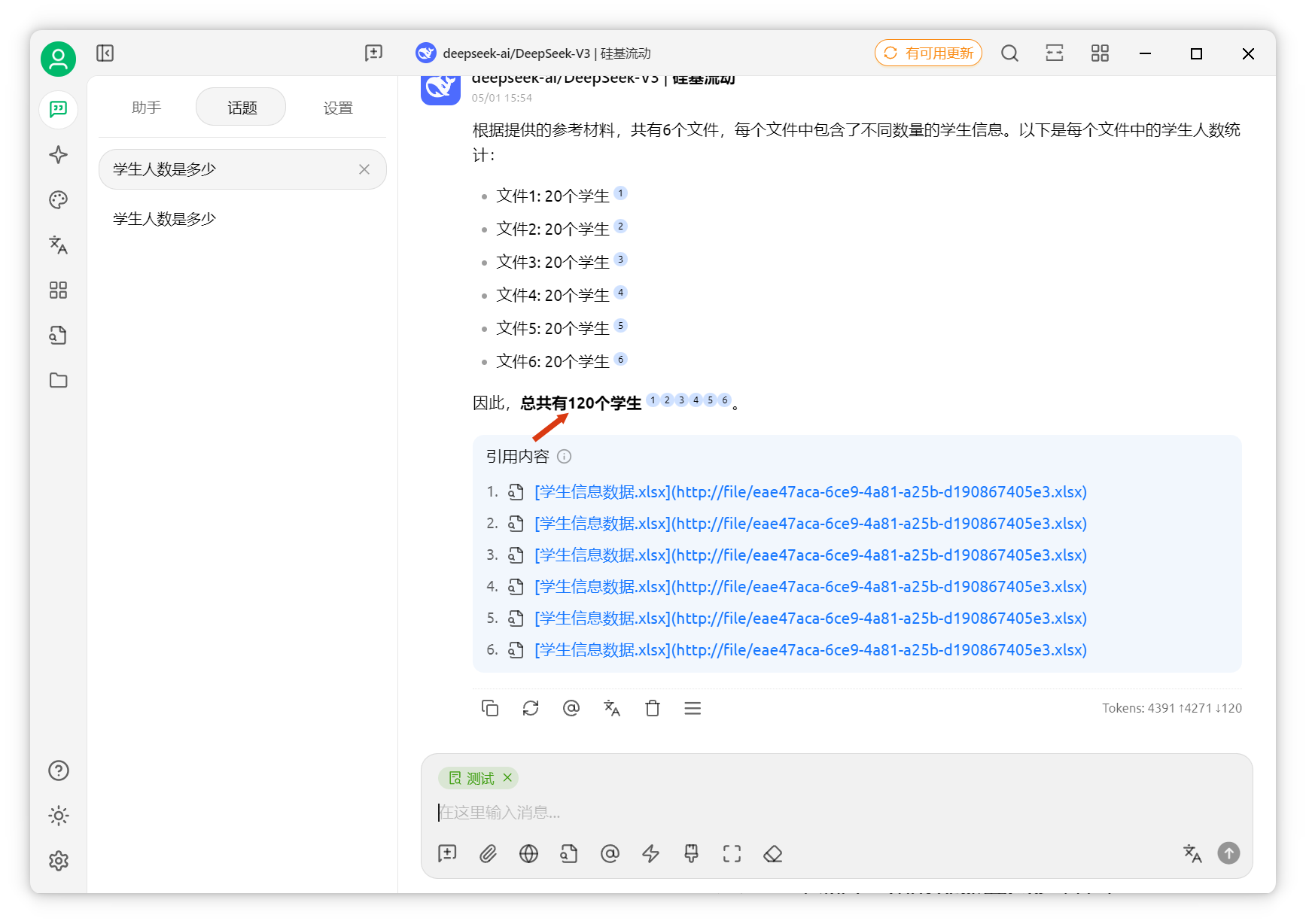
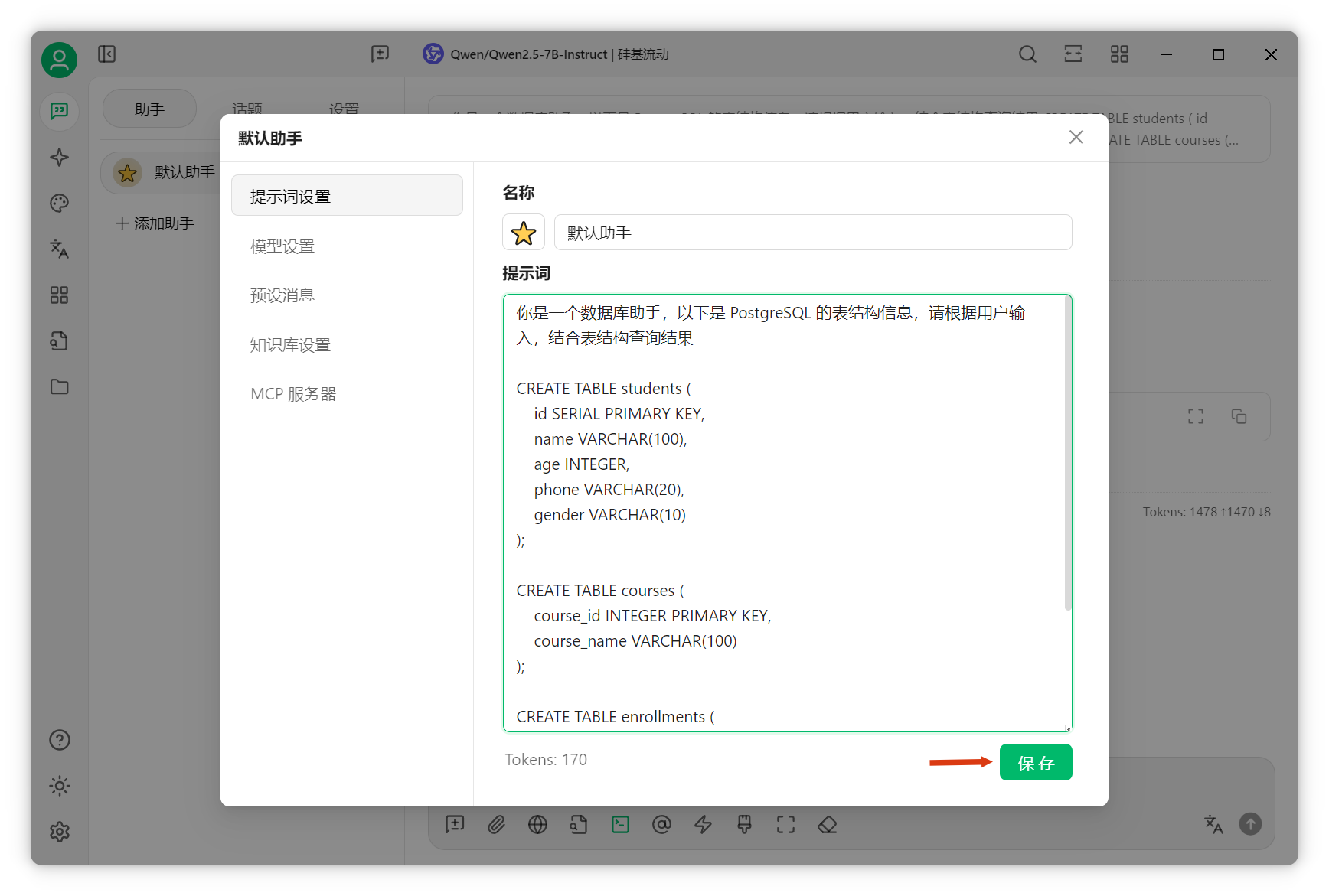
提問“共有多少學(xué)生”,AI僅獲取六個片段。
實際有300個學(xué)生。
AI卻答120個。
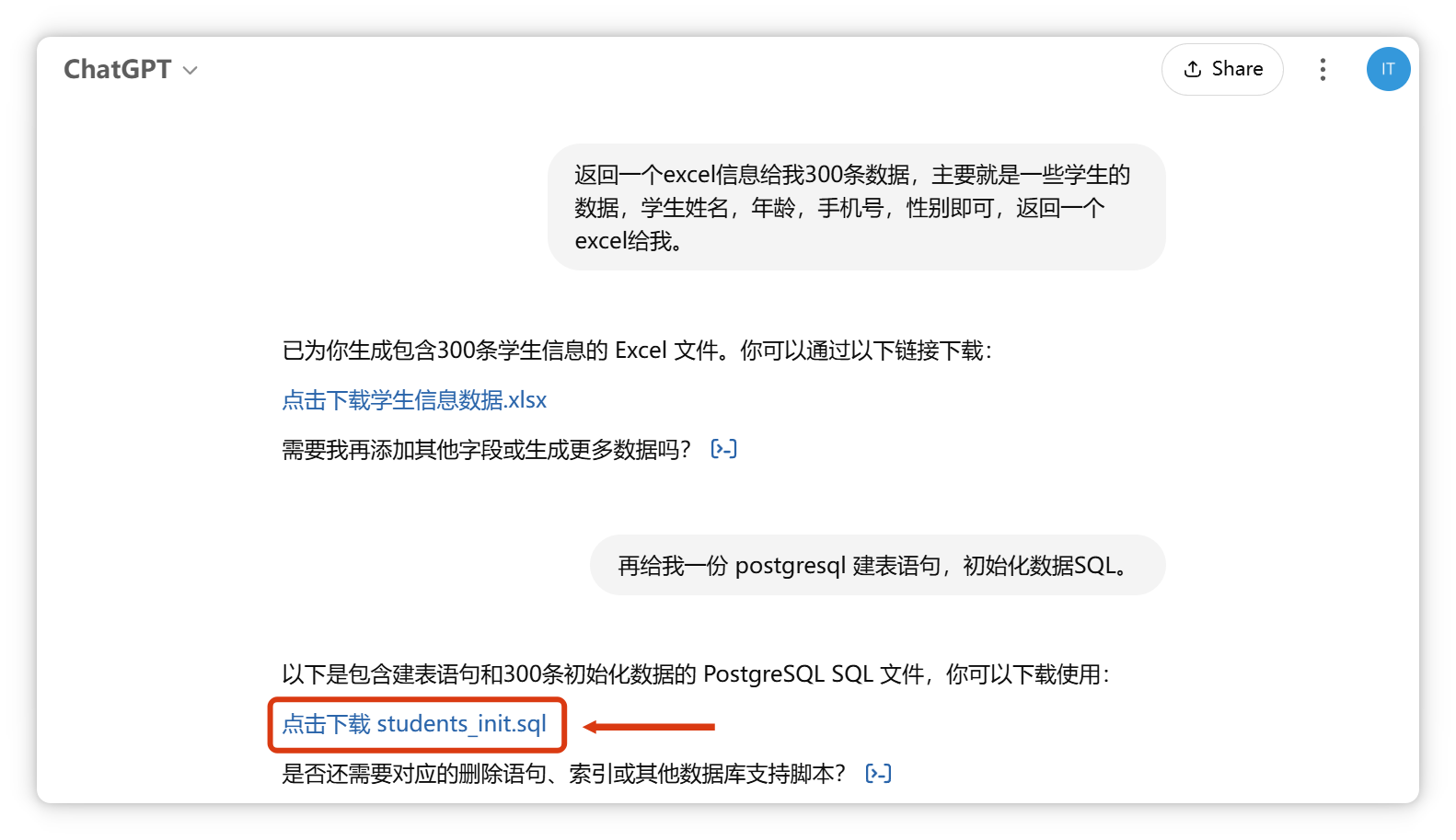
因此,結(jié)構(gòu)化或統(tǒng)計性問題建議用關(guān)系型數(shù)據(jù)庫。現(xiàn)在可通過MCP讓AI操作數(shù)據(jù)庫,效果更佳。 數(shù)據(jù)庫接入與配置已將學(xué)生數(shù)據(jù)導(dǎo)入PostgreSQL數(shù)據(jù)庫。 數(shù)據(jù)準(zhǔn)備與導(dǎo)入借助ChatGPT將Excel數(shù)據(jù)轉(zhuǎn)為SQL語句,高效導(dǎo)入數(shù)據(jù)庫。以下為效果截圖,敏感信息已脫敏。
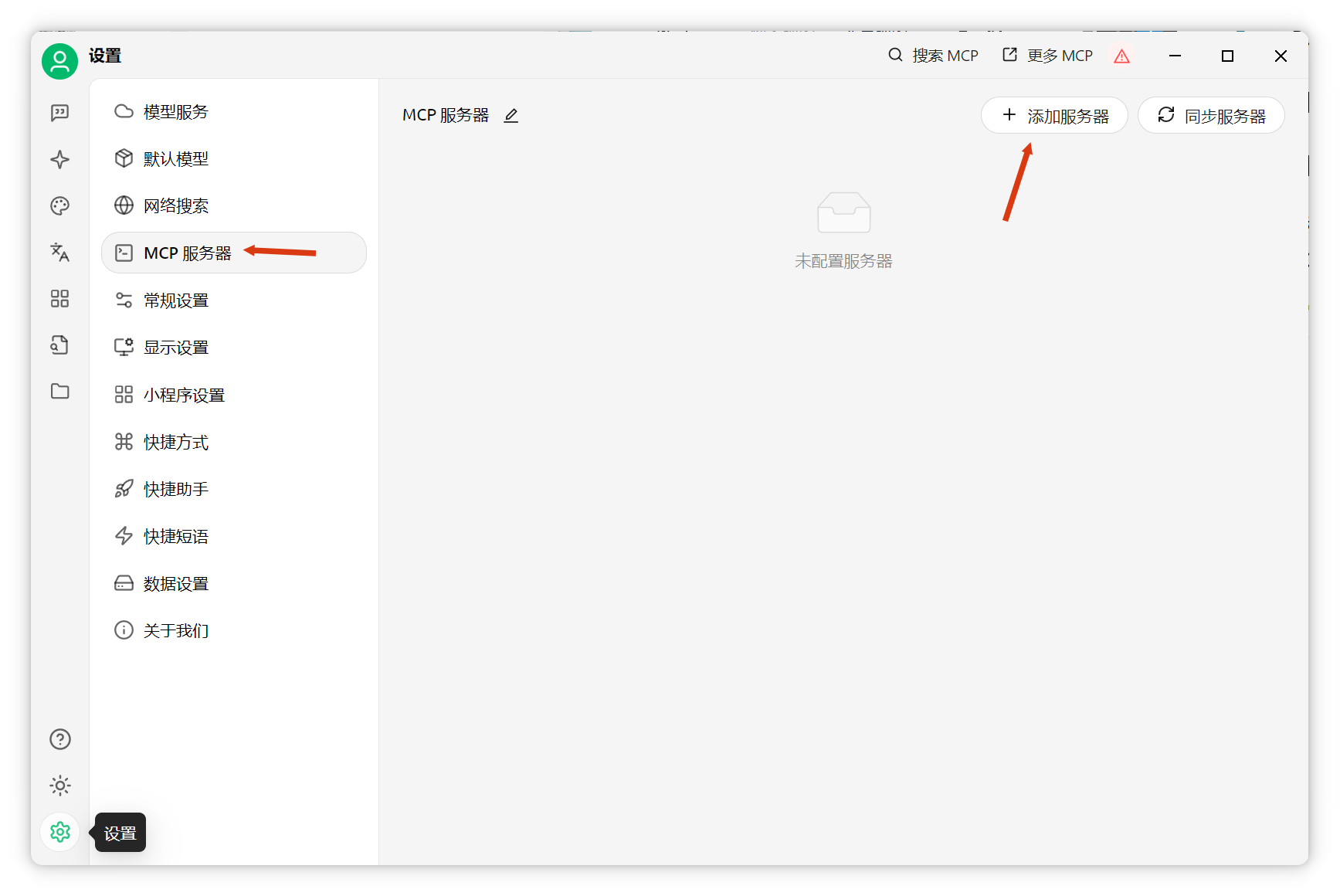
Cherry Studio環(huán)境配置在Cherry Studio配置MCP server,使AI可訪問數(shù)據(jù)庫。進入設(shè)置,添加MCP服務(wù)器。
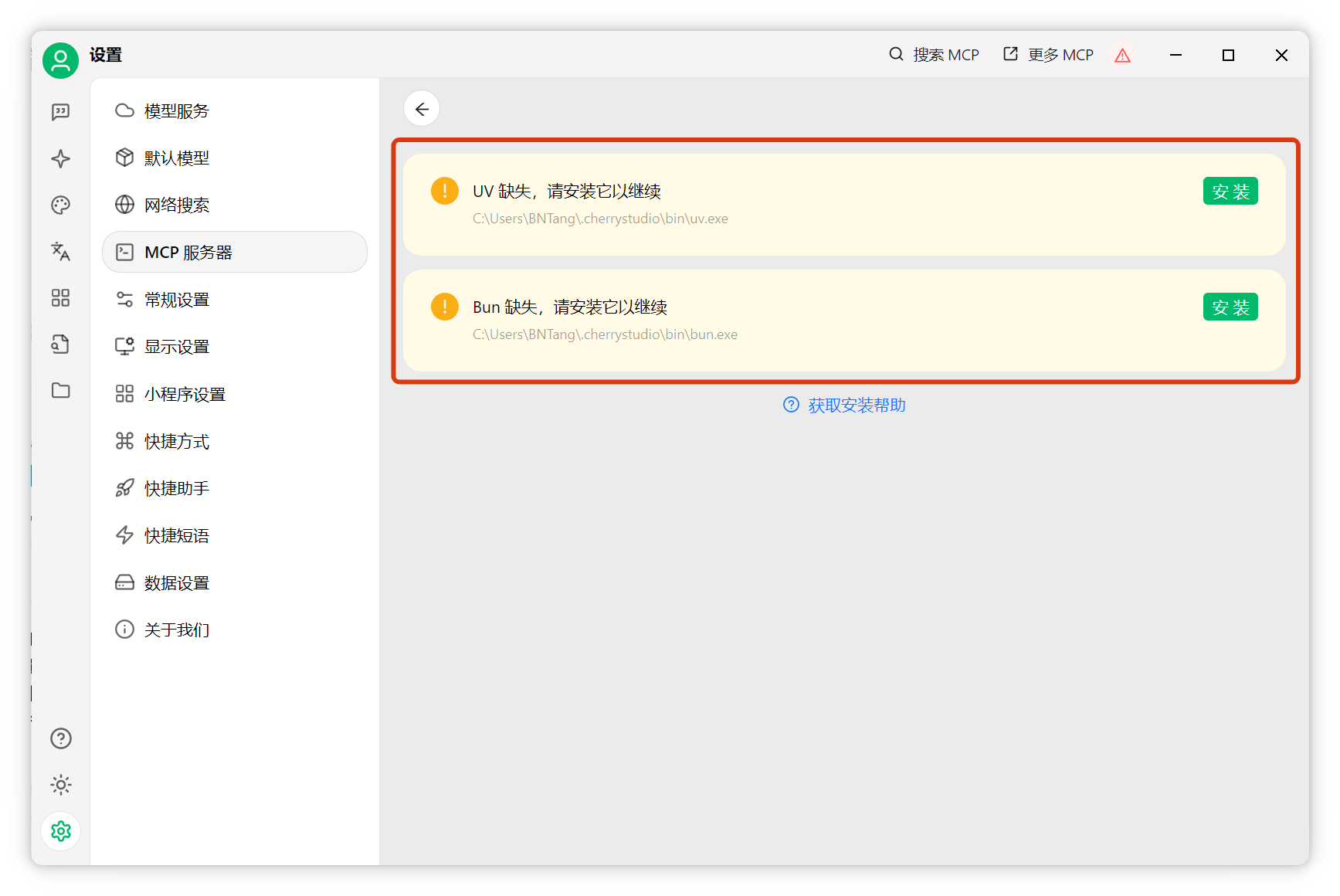
如出現(xiàn)紅色感嘆號,點擊查看詳情,按提示安裝UV和Bun依賴。
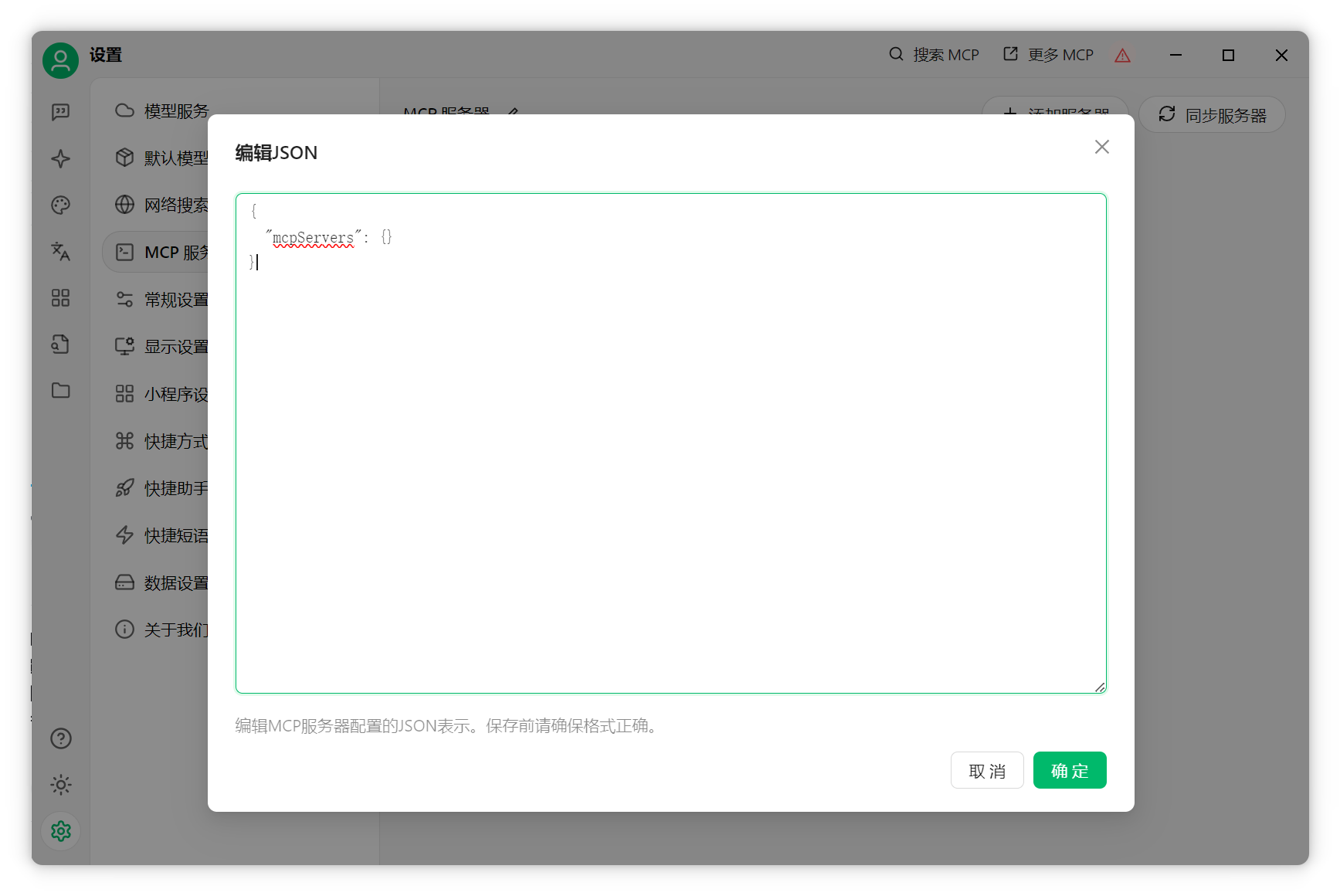
安裝完成后,編輯MCP配置。
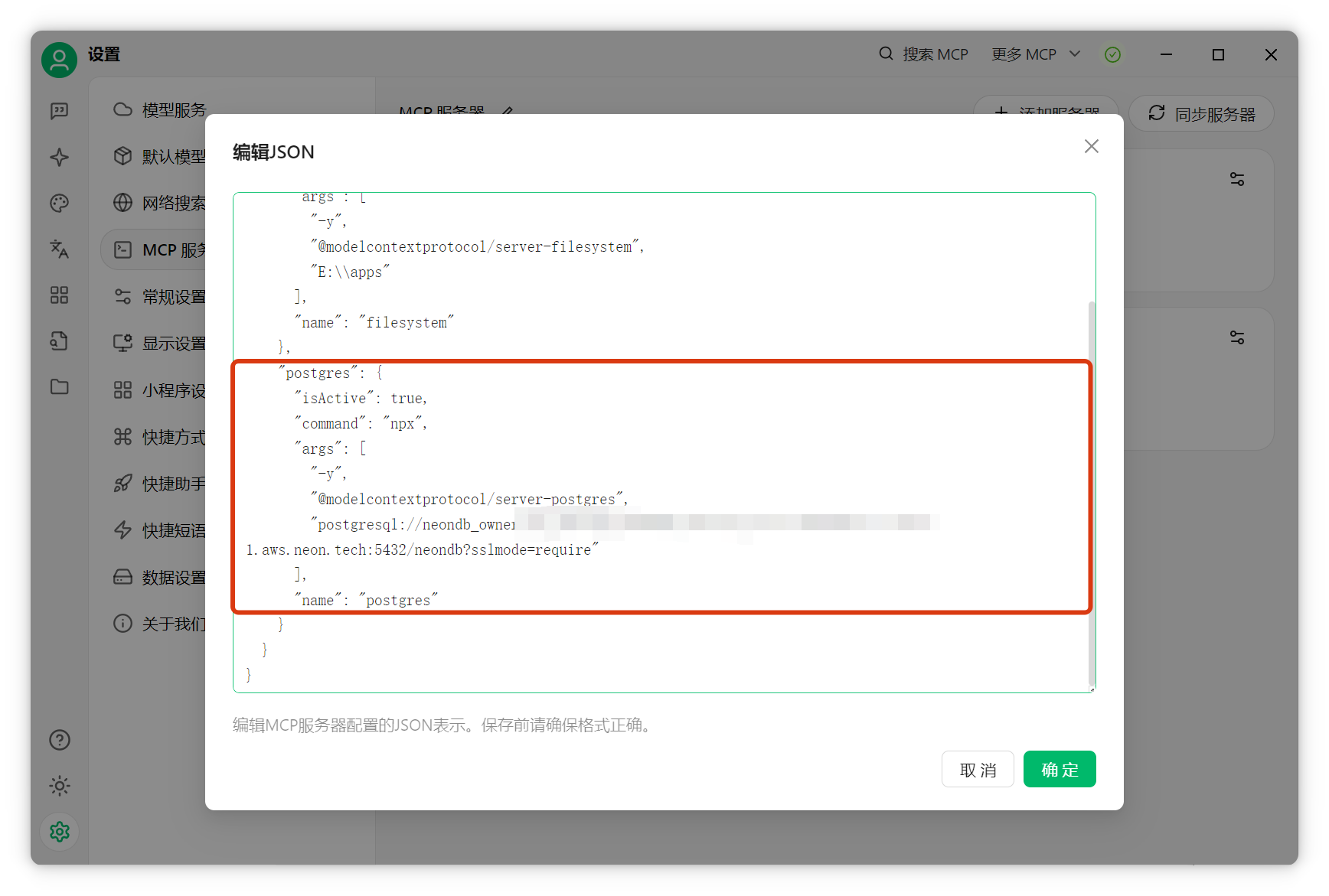
數(shù)據(jù)庫接入MCP Server在MCP配置頁面查找PostgreSQL MCP。可參考官方GitHub:PostgreSQL MCP 復(fù)制官方配置內(nèi)容,粘貼到Cherry Studio。
將 "postgresql://<user>:<password>@<host>:<port>/<database>" 示例(已脫敏): postgresql://db_user:db_password@db-host.example.com:5432/dbname?sslmode=require
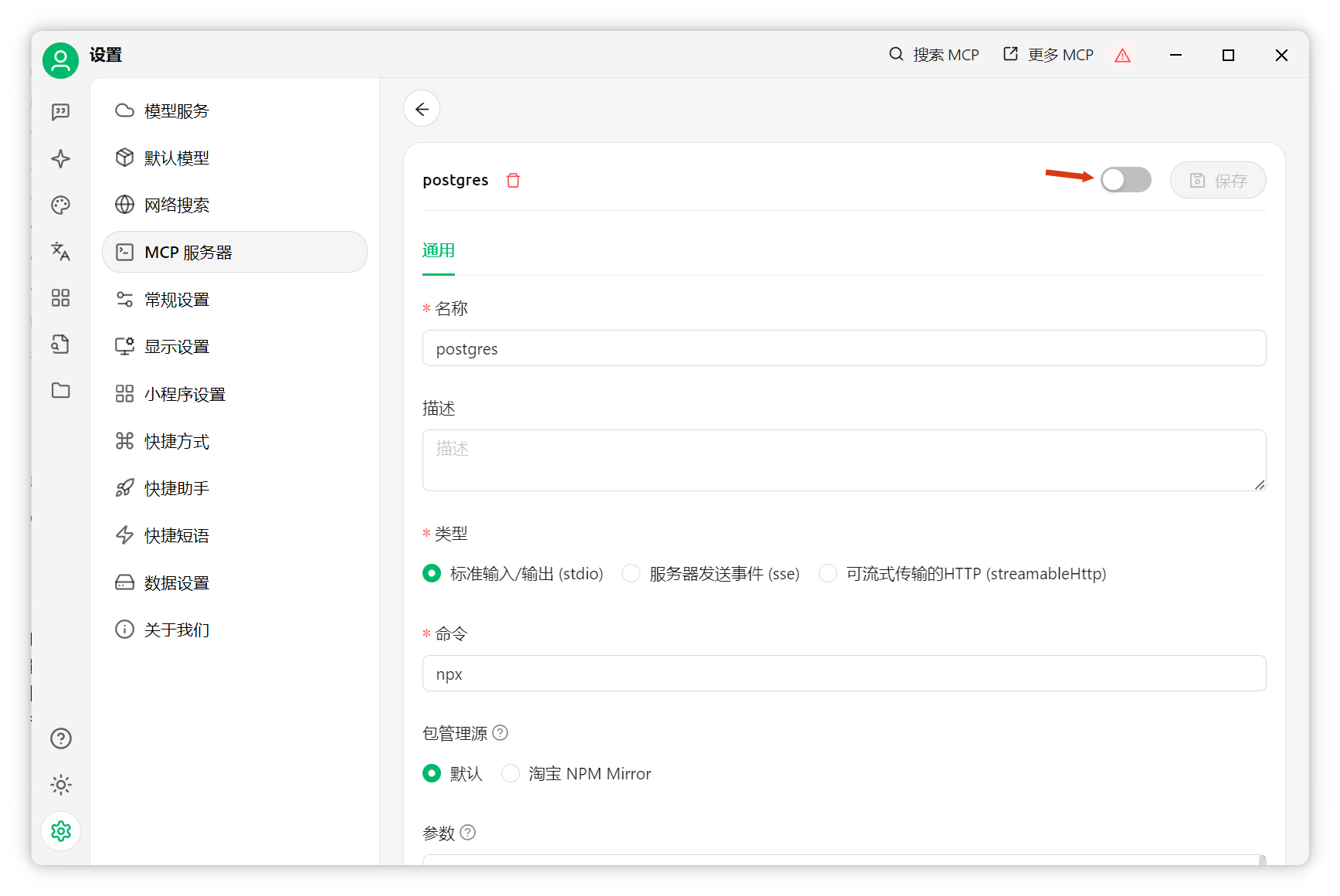
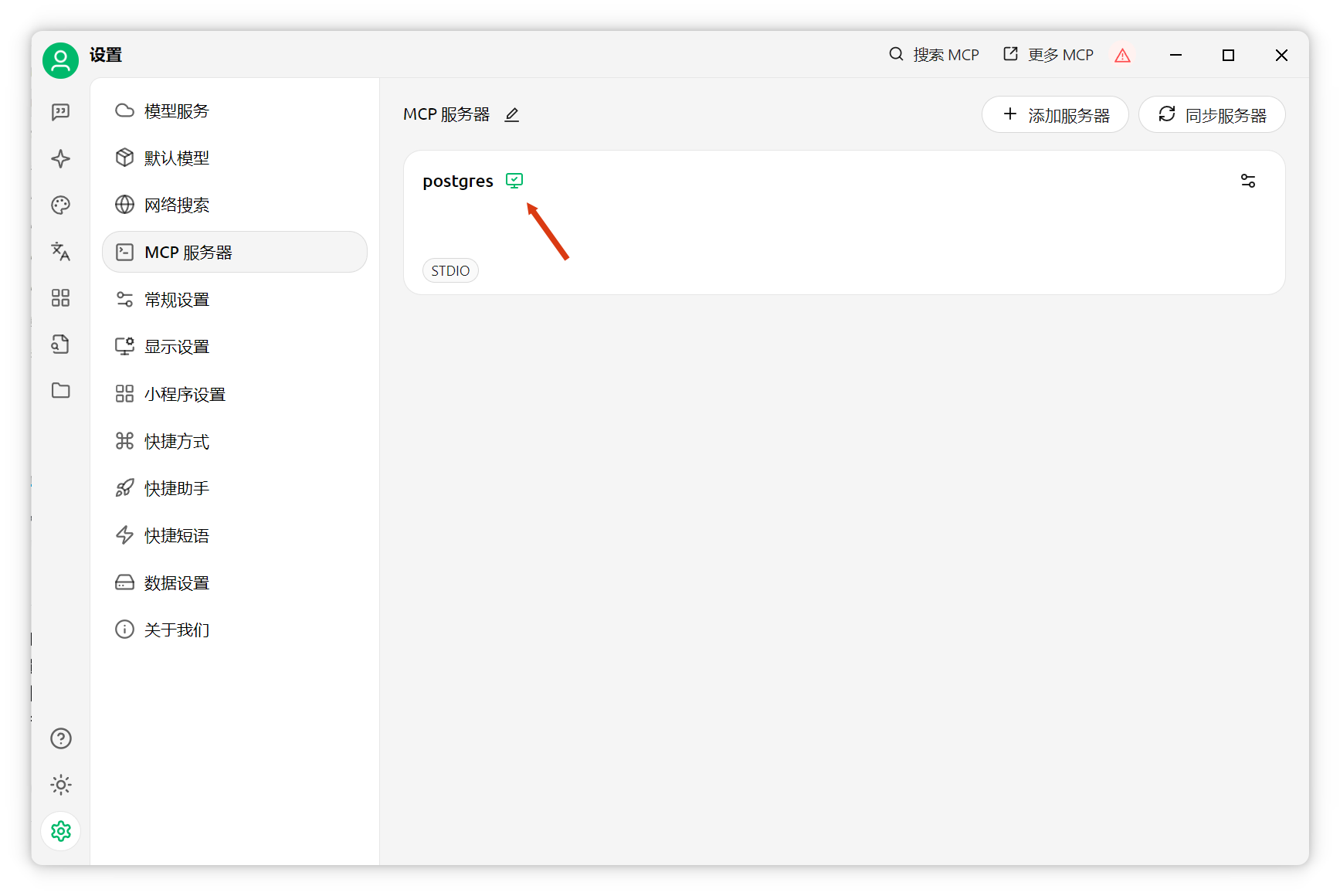
點擊確定,啟動服務(wù)。
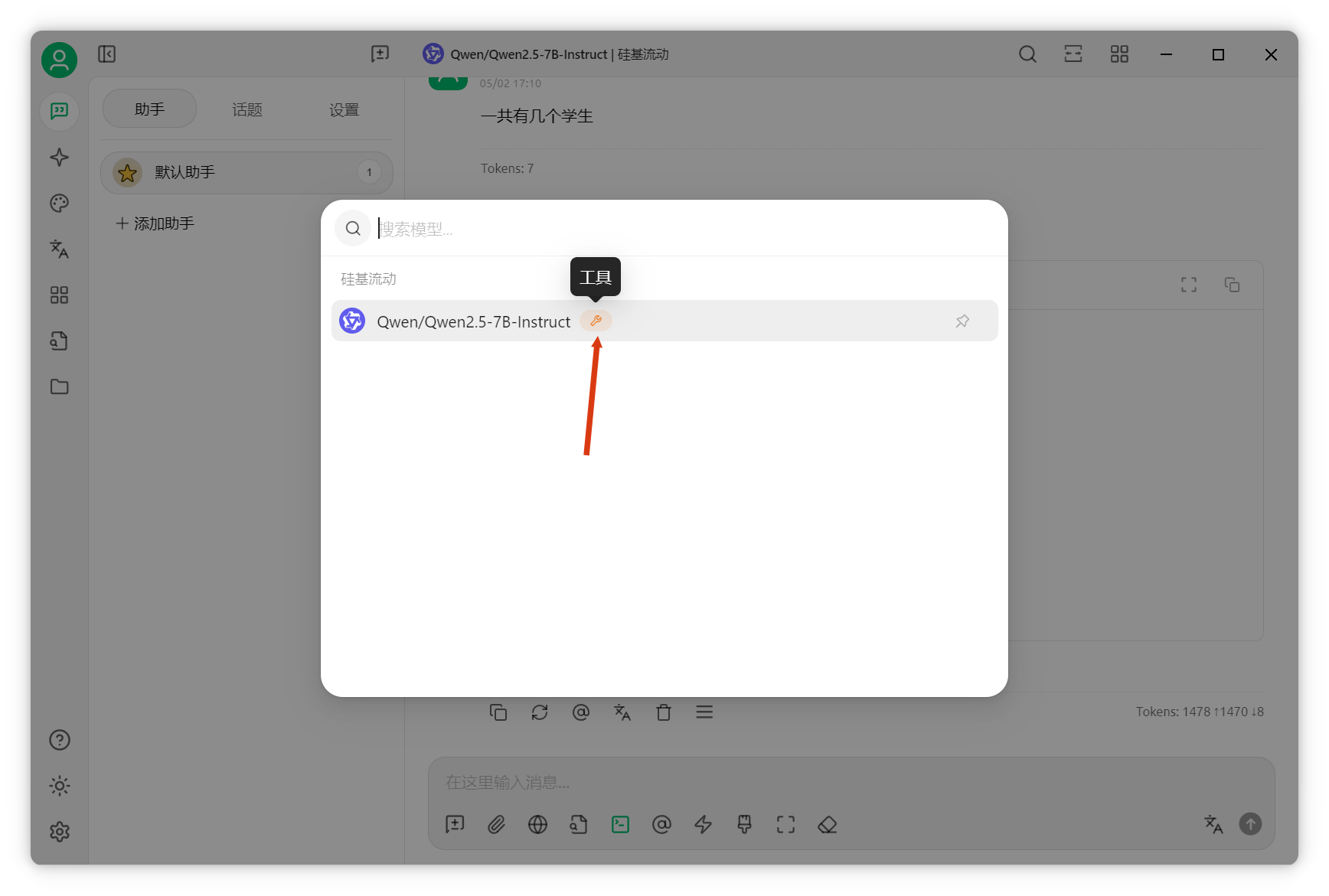
系統(tǒng)提示詞配置回到聊天界面(需選擇支持函數(shù)調(diào)用的模型,模型名后有扳手圖標(biāo)),選擇剛配置的Postgres MCP服務(wù)器。
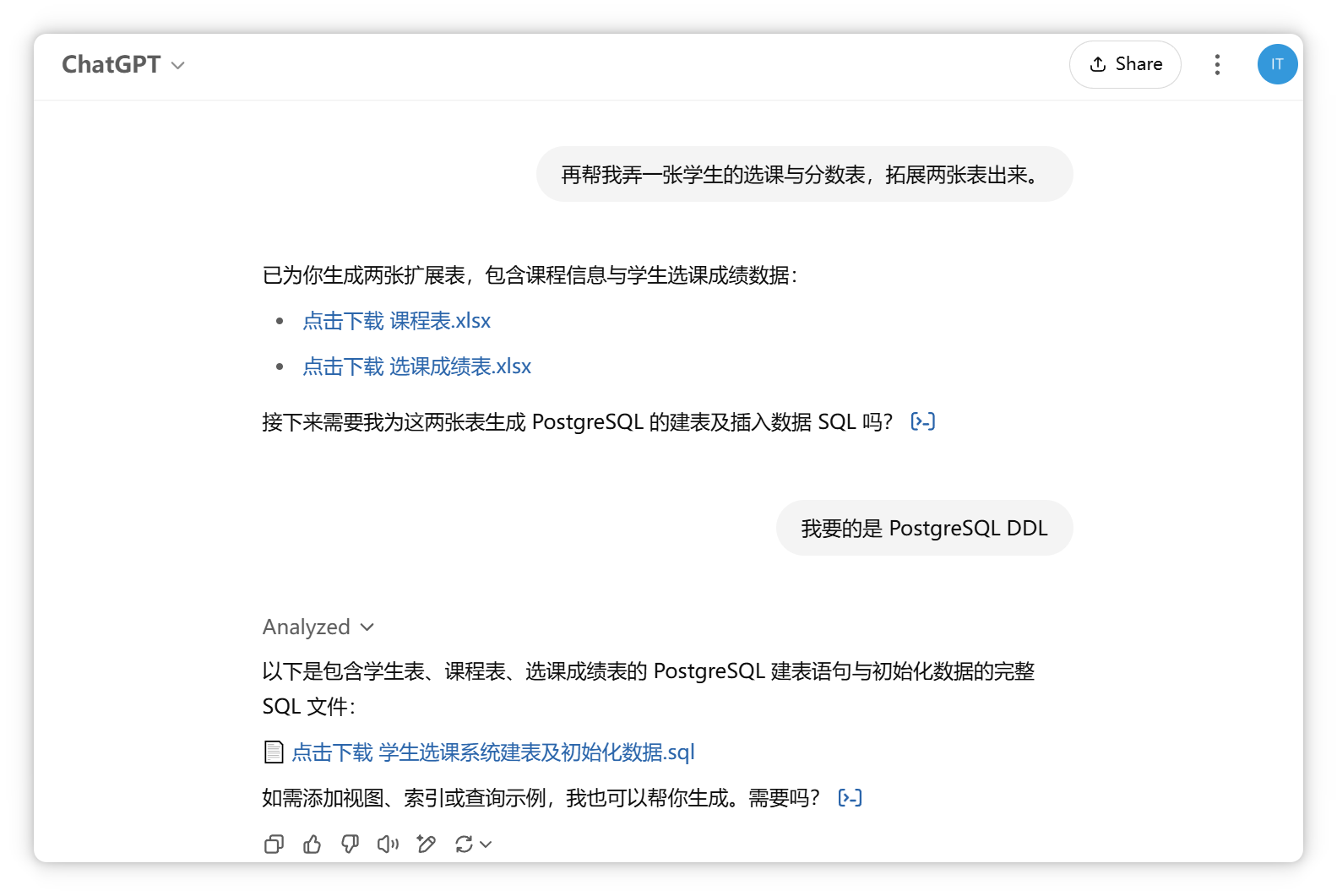
編輯系統(tǒng)提示詞,先提供數(shù)據(jù)庫表結(jié)構(gòu)信息。 擴展兩張表:課程表和選課成績表。
你是數(shù)據(jù)庫助手,以下是PostgreSQL表結(jié)構(gòu),請結(jié)合表結(jié)構(gòu)和查詢結(jié)果回答用戶問題。
CREATE TABLE students (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
age INTEGER,
phone VARCHAR(20),
gender VARCHAR(10)
);
CREATE TABLE courses (
course_id INTEGER PRIMARY KEY,
course_name VARCHAR(100)
);
CREATE TABLE enrollments (
id SERIAL PRIMARY KEY,
student_id INTEGER REFERENCES students(id),
course_id INTEGER REFERENCES courses(course_id),
score INTEGER
);
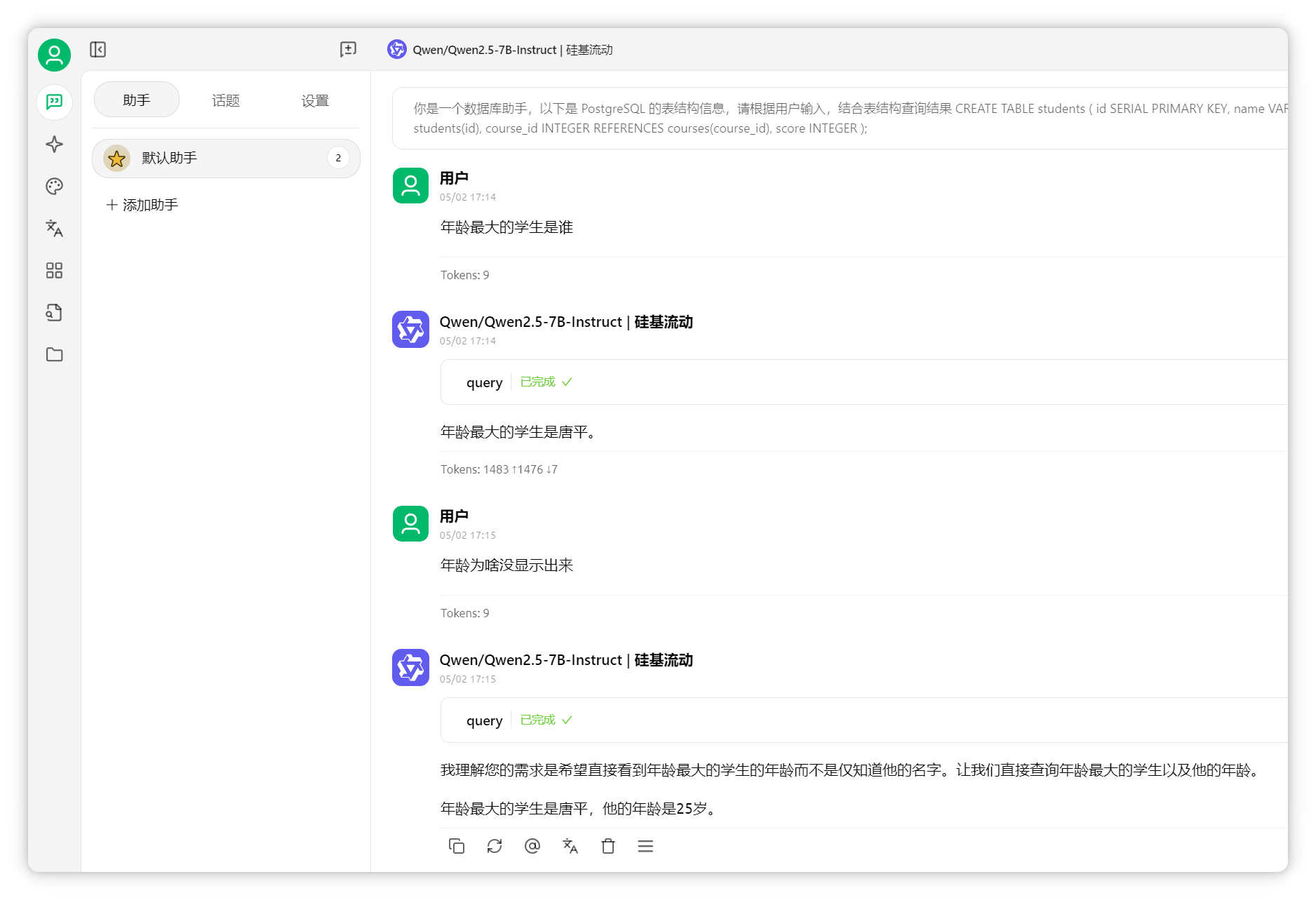
效果驗證保存后測試,如“學(xué)生總數(shù)是多少”。
AI可成功調(diào)用MCP server,通過SQL查詢返回結(jié)果。需選擇支持工具調(diào)用的模型。
再問“年齡最大的學(xué)生是誰”,同樣查詢成功。
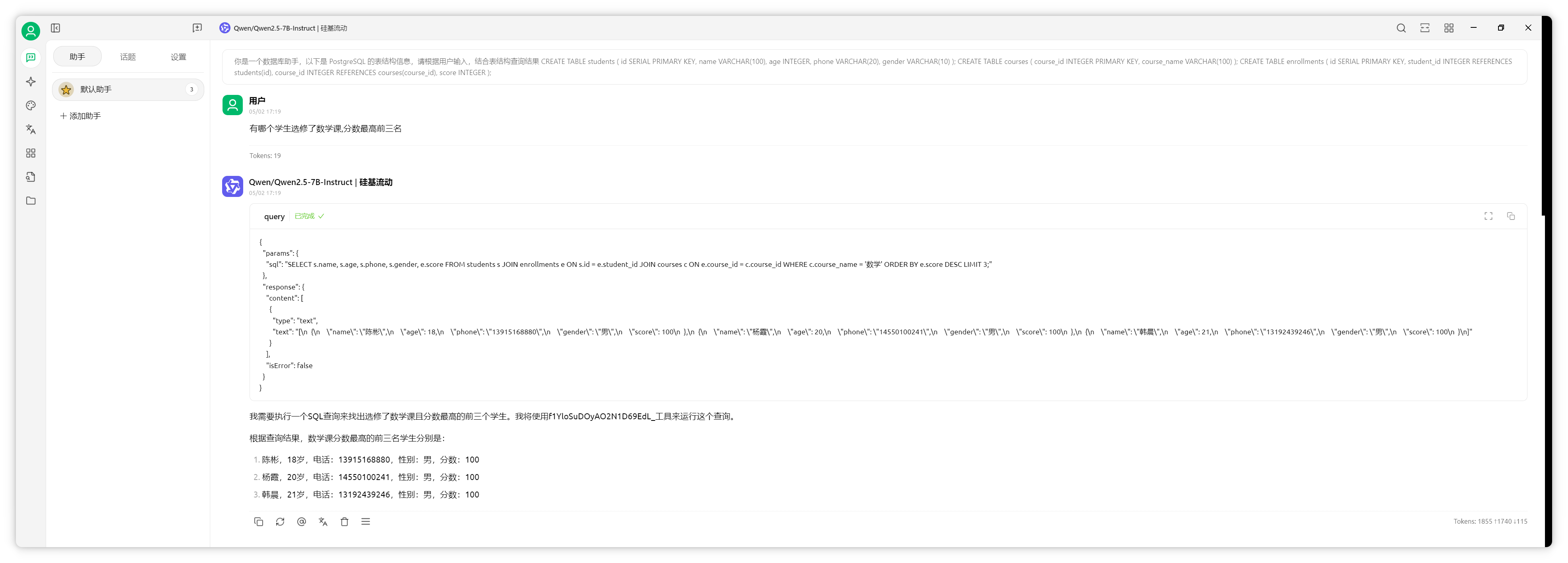
測試復(fù)雜問題,如“哪些學(xué)生選修了數(shù)學(xué)課,分?jǐn)?shù)最高前三名”。
AI可聯(lián)合三表查詢,準(zhǔn)確返回結(jié)果。通過MCP server對接數(shù)據(jù)庫,結(jié)構(gòu)化數(shù)據(jù)檢索效果遠超普通知識庫。 超長上下文模型的應(yīng)用此外,還可利用支持超長上下文的模型,將資料直接拖入對話框。
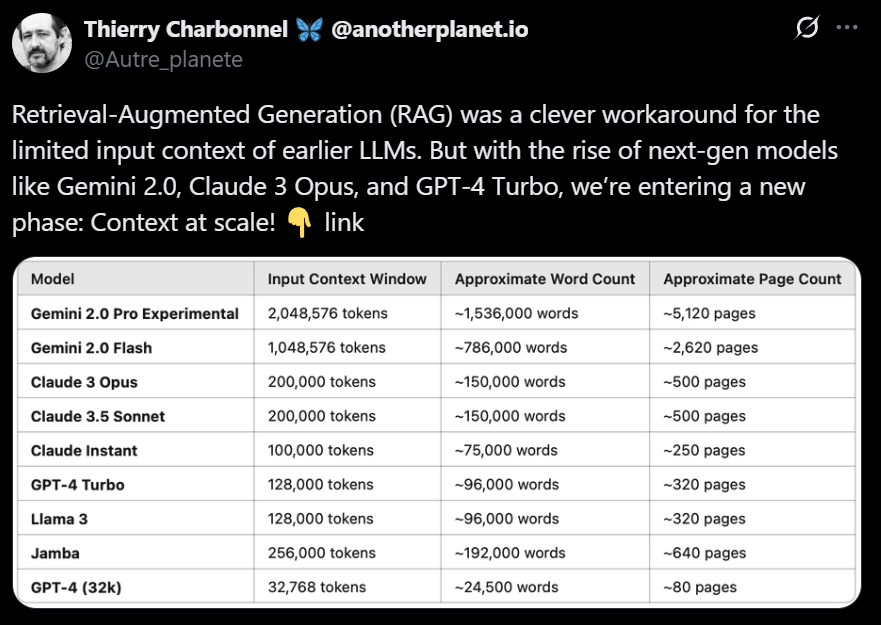
模型窗口進化與測試如上圖,近兩年模型上下文窗口大幅提升。例如Gemini 2.0 Pro已支持2000萬token,可容納四大名著。以下以Gemini為例測試。 API密鑰獲取與模型配置訪問谷歌AI Studio(需魔法上網(wǎng))。
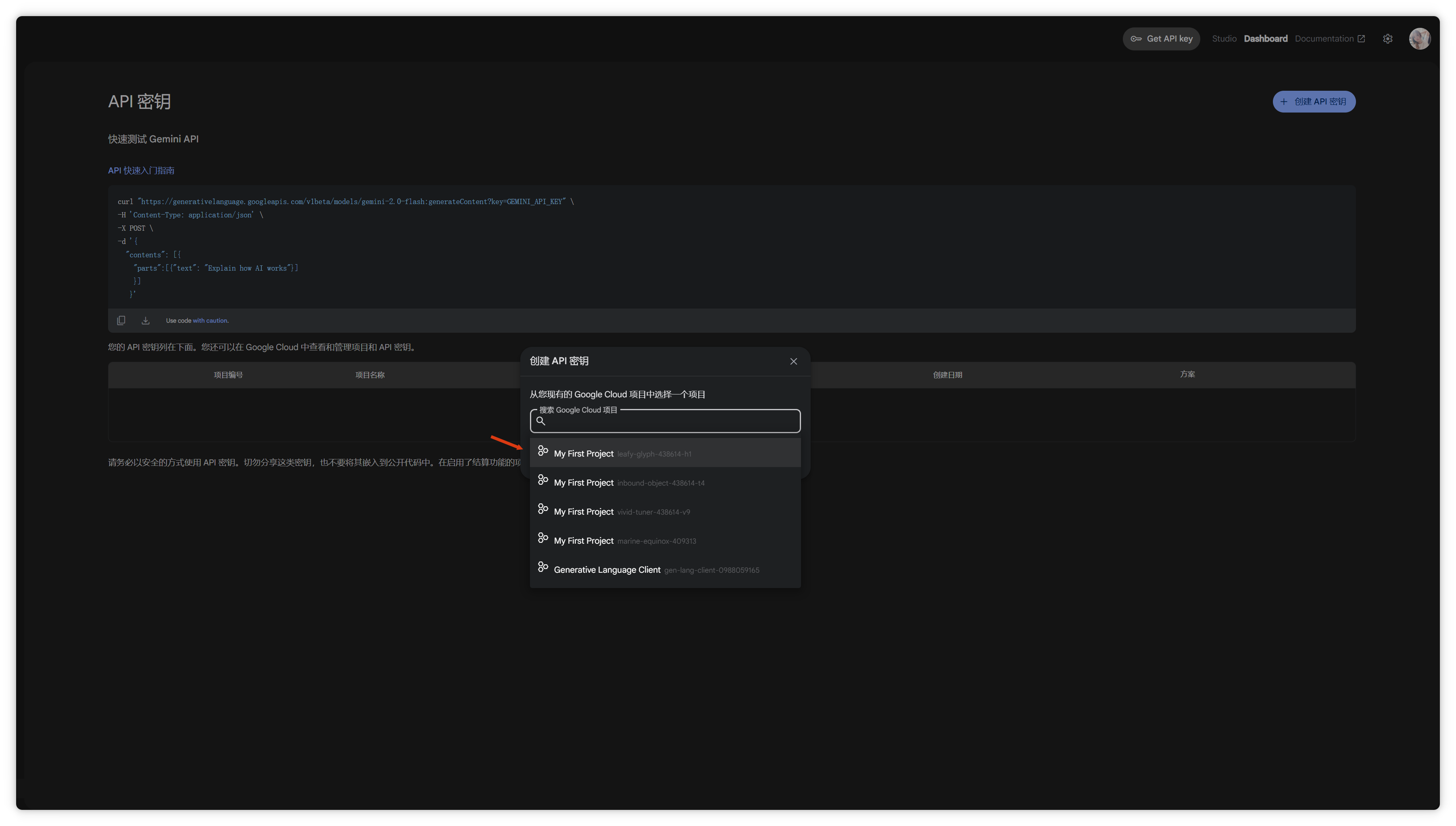
右上角“Get API Key”,點擊創(chuàng)建API密鑰。
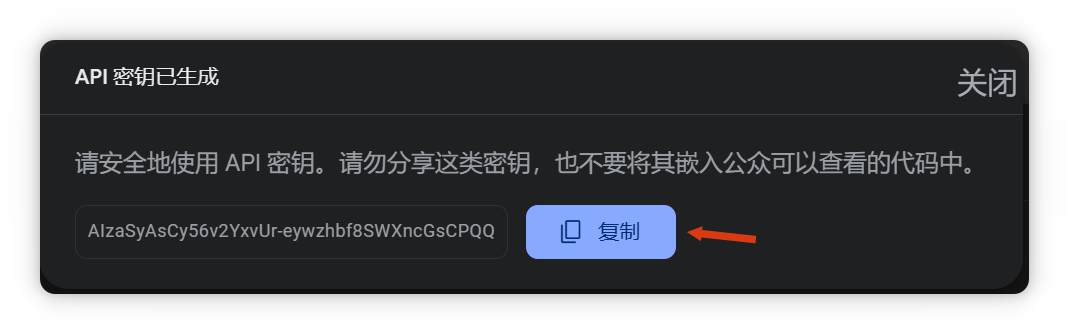
復(fù)制API密鑰。
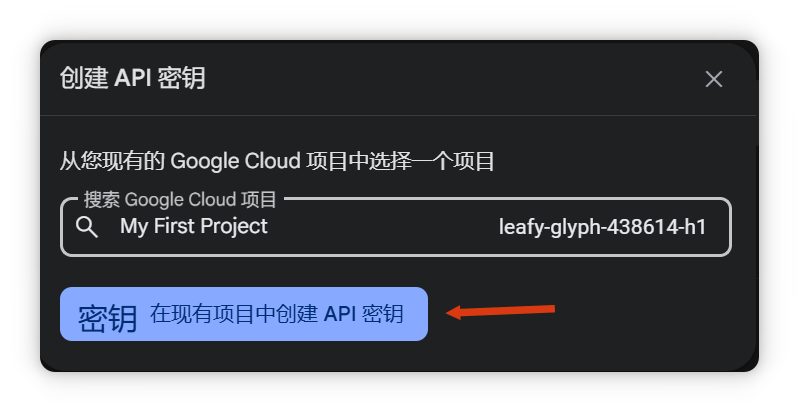
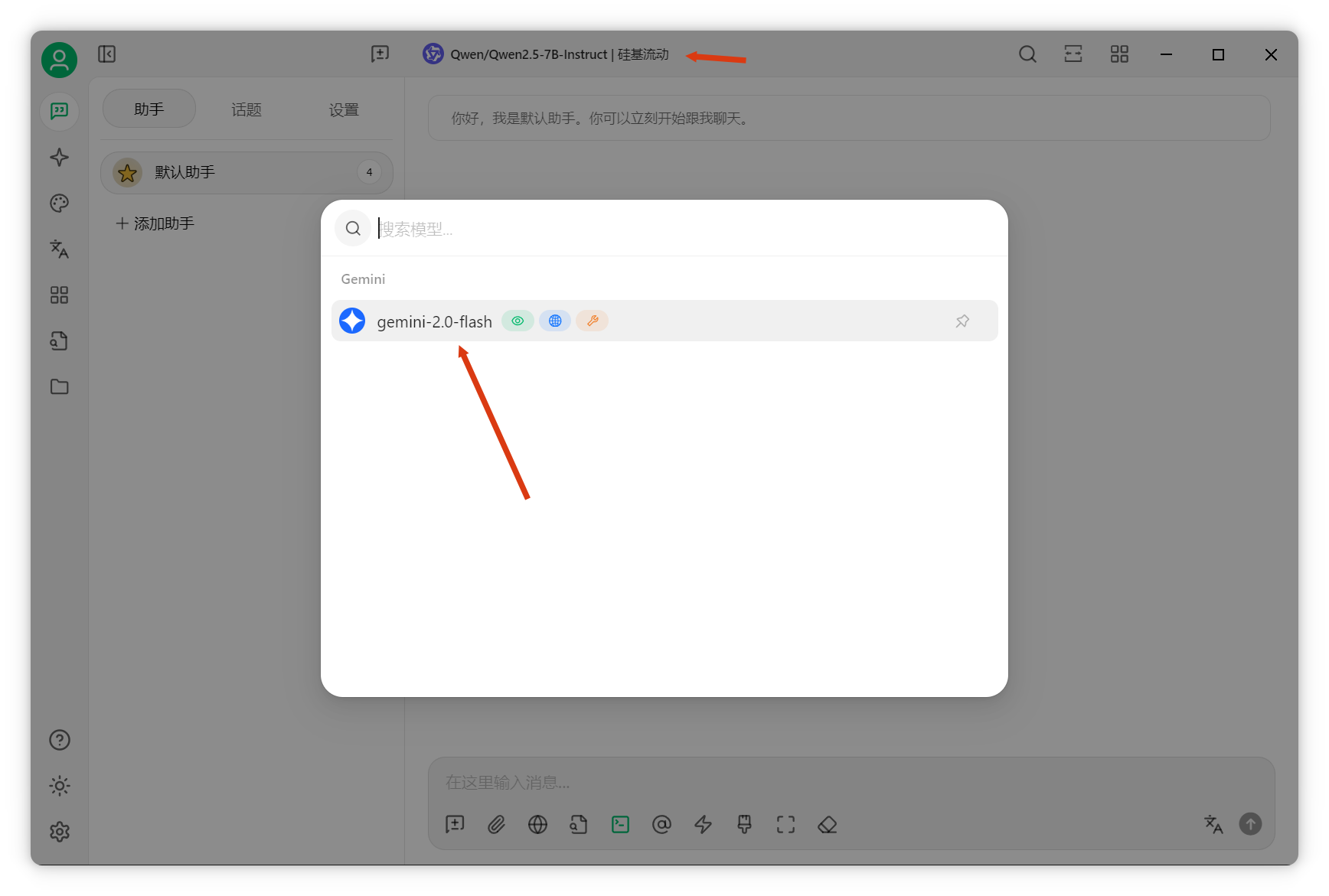
回到Cherry Studio,設(shè)置模型服務(wù)商為Gemini,填寫API密鑰。
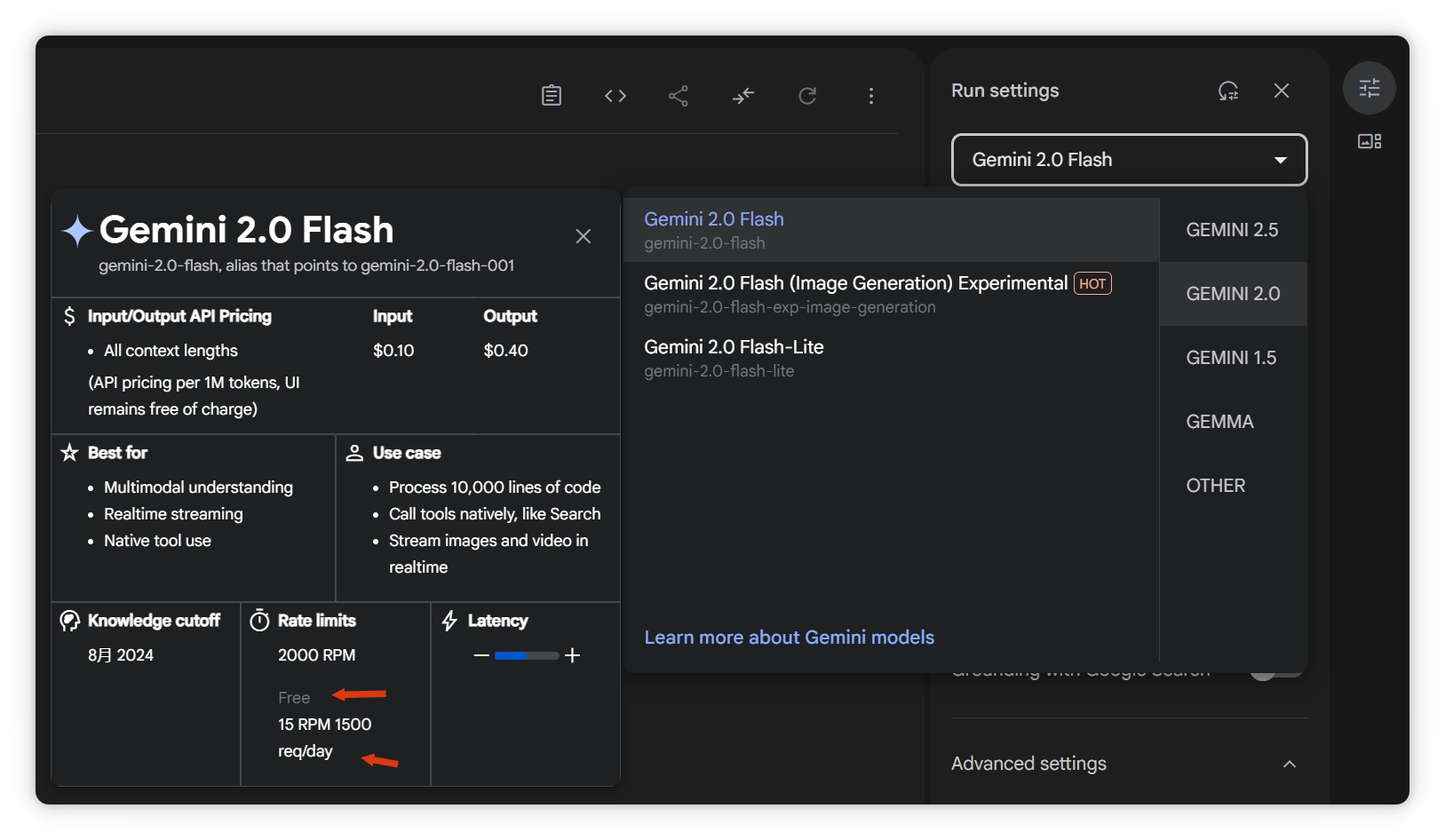
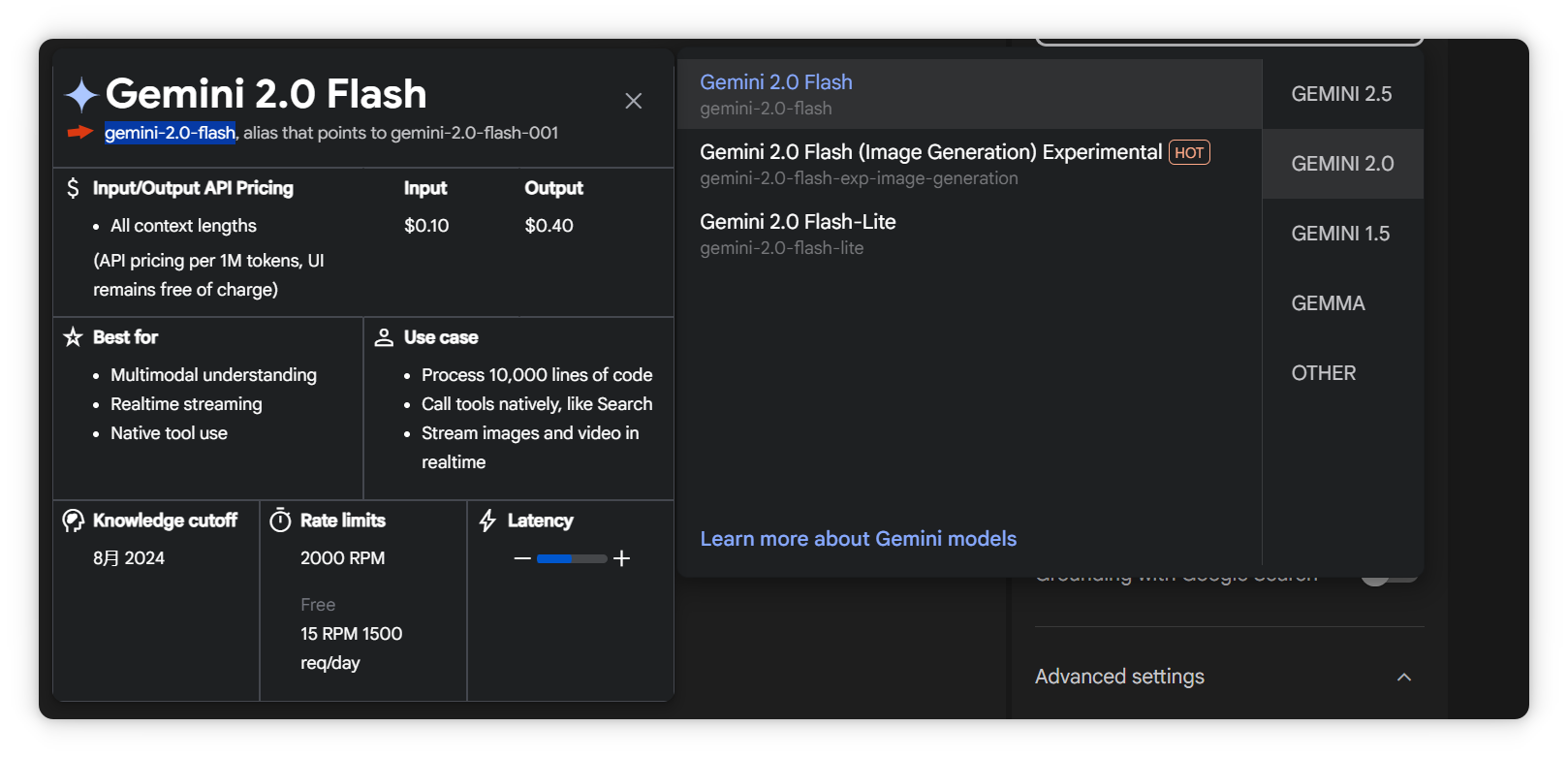
添加模型,點擊“添加”,模型ID可在AI Studio選擇。以Gemini 2.0 Flash為例,支持100萬token上下文,且有免費額度。
復(fù)制Gemini 2.0 Flash模型ID。
回到Cherry Studio,填寫模型ID并添加。
切換聊天模型為Gemini 2.0 Flash。
清空助手默認Prompt。
知識庫檢索實戰(zhàn)測試知識庫能力。以全本《三國演義》為例,用VSCode將張飛武器改為“丈九棒棒糖”,保存。
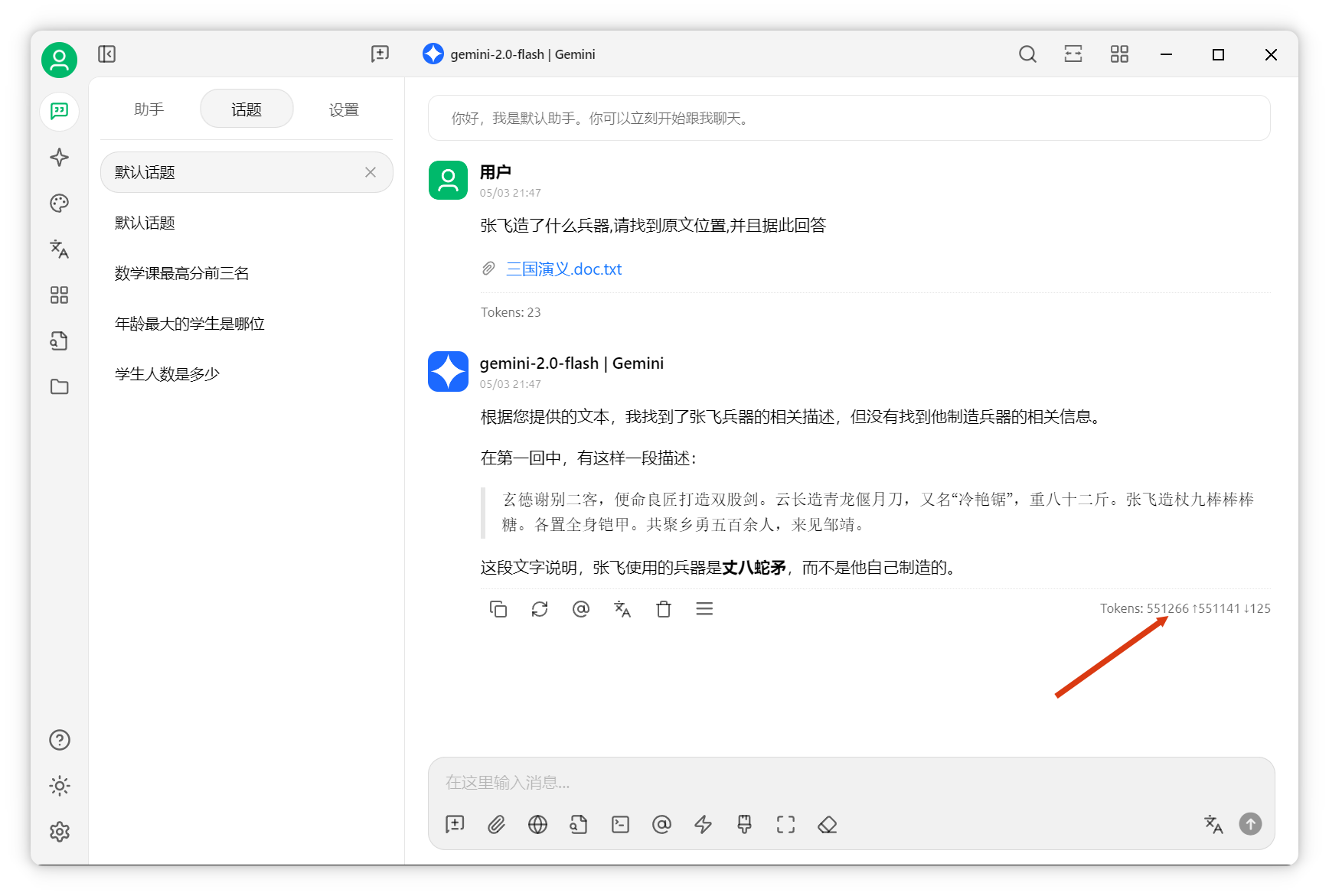
將全本《三國演義》拖入對話框,提問:“張飛造了什么兵器,請找到原文位置并據(jù)此回答。”
AI成功檢索到答案,第一回中張飛造“丈九棒棒糖”。本次任務(wù)消耗551266 token。
整個《三國演義》僅用了一半上下文窗口。利用Gemini超長上下文進行知識庫檢索,效率極高。 總結(jié)與展望AI知識庫常被稱為“demo五分鐘,上線一年”。目前AI知識庫仍是復(fù)雜系統(tǒng)工程,無通用銀彈,項目落地需多工具協(xié)作。當(dāng)前效果較好的方案是自適應(yīng)RAG,根據(jù)查詢類型自動選擇檢索策略,結(jié)合多種方式提升精度。本文到此結(jié)束. ?轉(zhuǎn)自https://www.cnblogs.com/BNTang/p/18861128 該文章在 2025/5/8 8:57:00 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")