? Github Star: 34.3k[1]
? 官網(wǎng)[2]
Tesseract.js 是一個(gè)基于 JavaScript 的開源 OCR(光學(xué)字符識別)引擎。

Tesseract.js 是什么?
Tesseract.js 是一個(gè)純 JavaScript 庫,它提供了在瀏覽器中運(yùn)行 Tesseract OCR(光學(xué)字符識別)引擎的能力。由 Google 維護(hù)的開源 OCR 引擎,可以識別多種語言的文本,包括自動文本方向和腳本檢測,以及提供簡單的接口來讀取段落、單詞和字符的邊界框。通過 Tesseract.js 可以在不依賴服務(wù)器的情況下,直接在客戶端瀏覽器中處理圖像中的文本識別任務(wù)。具有以下特點(diǎn):
? 多語言支持:支持超過 100 種語言的文字識別,覆蓋了全球大部分的文字系統(tǒng),包括英文、中文、法文、德文等。
? 簡單易用的 API:提供了簡潔的 API,使得實(shí)現(xiàn)基本的 OCR 功能變得簡單。
? 高度可定制:支持設(shè)置識別語言、識別模式等參數(shù),還提供了多頁識別、手寫字體識別等高級功能。
? 實(shí)時(shí)識別:支持靜態(tài)圖像識別以及視頻流的實(shí)時(shí)文字識別。
快速開始
安裝
安裝 Tesseract.js 可以通過 CDN 或 npm/yarn 進(jìn)行。
npm install tesseract.js
# yarn
yarn add tesseract.js
在瀏覽器中,可以直接通過 CDN 引入 Tesseract.js,或者在 Node.js 項(xiàng)目中通過 npm 安裝。
入門示例
安裝完成后,需要引入 Tesseract.js,可以使用 ES6 的 import 語法引入。下面使用 import 語法引入的示例。
// 從 Tesseract 庫中解構(gòu)出 createWorker 函數(shù)
import { createWorker } from "tesseract.js";
// 獲取按鈕元素
const btn = document.querySelector('#btn')
// 為按鈕添加點(diǎn)擊事件監(jiān)聽器
btn.addEventListener('click', async () => {
// 獲取圖片元素
const image = document.querySelector('img')
// 創(chuàng)建一個(gè) Tesseract worker,使用中文簡體識別模型
const worker = await createWorker('chi_sim')
// 使用 worker 識別圖片中的文字
const result = await worker.recognize(image)
// 在控制臺輸出識別結(jié)果
console.log(result.data.text)
// 將識別結(jié)果顯示在頁面上
document.querySelector('#result').innerHTML = result.data.text
// 終止 worker,釋放資源
worker.terminate()
})
通過簡單的幾行代碼,實(shí)現(xiàn)中文圖片的 OCR 文字識別,看效果識別率還是挺高的。
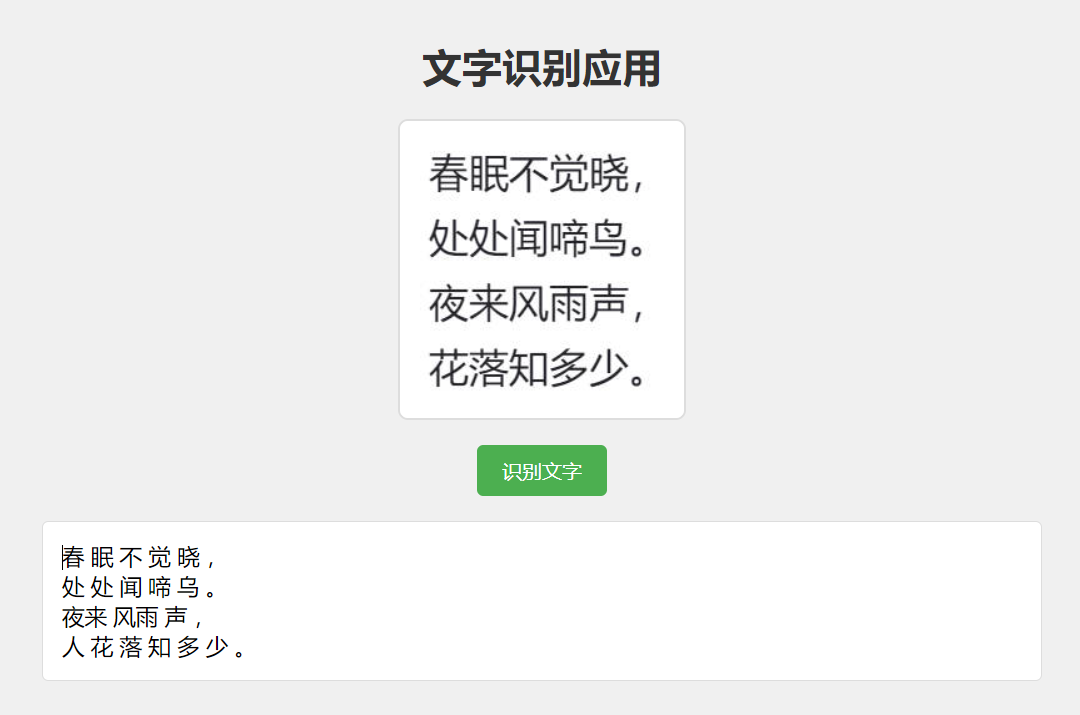
更多功能
上面我們只是簡單演示了 Tesseract.js 如何識別中文的。他還是支持更多高級的功能。如多語言識別、自定義識別參數(shù)、PDF 輸出等。它還進(jìn)行了多項(xiàng)性能優(yōu)化,包括文件大小優(yōu)化、內(nèi)存使用優(yōu)化和并行處理支持。
識別效果受到圖片質(zhì)量、文字清晰度、字體樣式等多種因素的影響。因此,在實(shí)際應(yīng)用中,你可能需要對圖片進(jìn)行預(yù)處理(如裁剪、旋轉(zhuǎn)、縮放、增強(qiáng)對比度等)以提高識別準(zhǔn)確率。
總結(jié)
Tesseract.js 是一個(gè)功能強(qiáng)大、易于使用的 OCR 庫,具有廣泛的應(yīng)用場景和廣闊的發(fā)展前景。希望本期推薦能幫到你!
祝好!
引用鏈接
[1] Github Star: 34.3k: https://github.com/naptha/tesseract.js
[2] 官網(wǎng): https://tesseract.projectnaptha.com/
該文章在 2024/10/11 8:59:56 編輯過
晴ERP是一款針對中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

